*Lynn 給讀者的前言:先說,這篇文章很長,高達 1.2 萬字的深度長文,是我目前網站上發表過最長的一篇文章,也是我差點寫到斷氣的一篇。但希望對於 AI、對於台積電、對於記憶體、對於 NVIDIA 與 AMD 與半導體產業關注的你一定要看完。
這篇文章會回答很多人好奇的問題:
- 到底什麼是 HBM(高頻寬記憶體)?跟傳統記憶體差在哪?
- HBM 與台積電的 CoWoS 技術和 NVIDIA GPU 又有什麼關係?
- SK 海力士與三星的技術誰強、三星有可能追上嗎?
- AI 半導體到底退燒了沒有?
但我保證看完這篇文章的你,除了了解上述問題之外,最重要的還是,將會深刻地感受到何謂 AI 半導體群雄爭霸的刺激動盪,與人類創新高速發展的魅力。

AI 顯示卡中最昂貴的必需品:HBM 記憶體
在訓練像 ChatGPT 這樣的 LLM 大型語言模型時,會需要高達幾百億、甚至幾千億個參數。GPT-3 已經擁有 1,750 億個參數 (175B),而 GPT-4 模型甚至據說有數萬億個參數(由多個 220B 模型組成),開源軟體 Llama 3.1 參數規模也已經成長到了 405B。參數決定了模型如何處理輸入的資料來生成對應內容,比如文法、單字、斷句等。
訓練的資料量與參數越多,AI 模型的能力也會越複雜與越強悍,從一開始 GPT-3 的單純語言翻譯、小段文本生成、簡易問答,到後面 GPT-4 可以撰寫專業的論文和進行繪畫音樂等各式各樣的藝術創作。
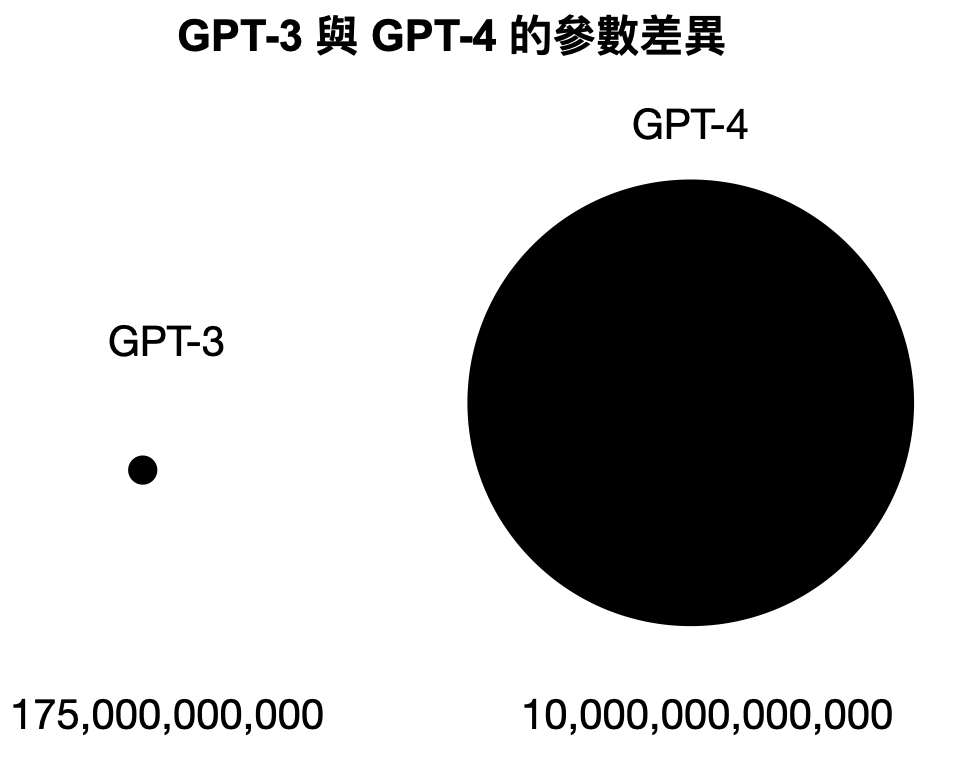
而參數量級的差距,也造就了 GPT-3 與 GPT-4 之間的能力差距就像太陽與地球的比例。

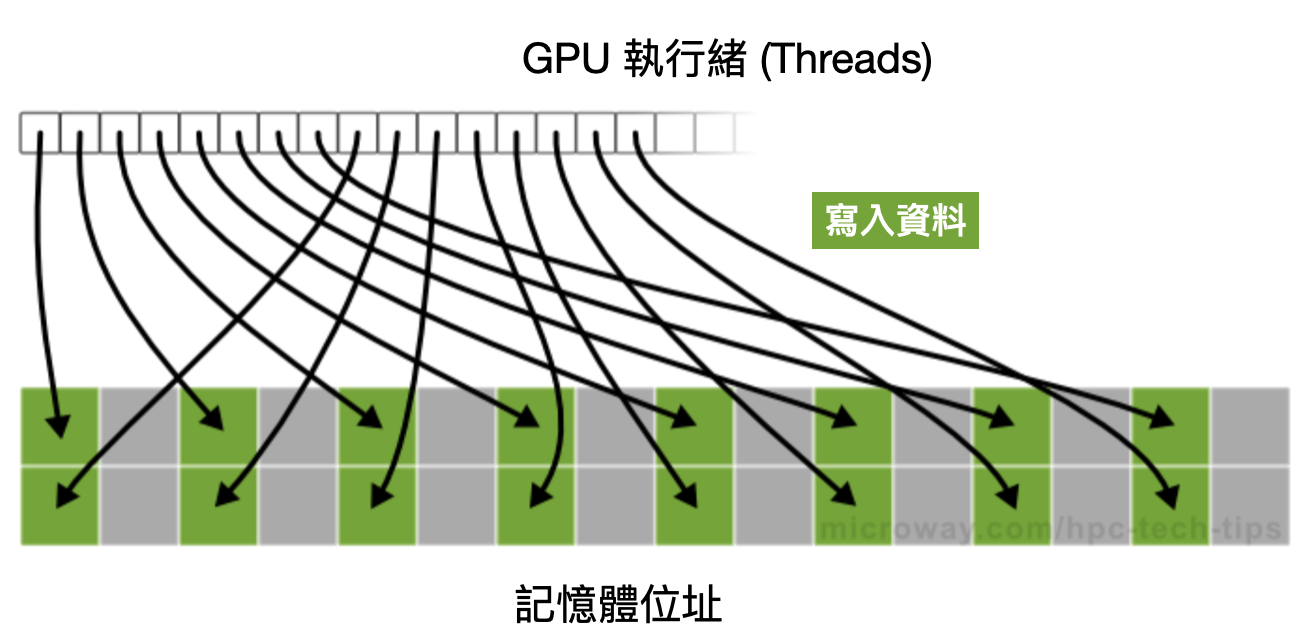
訓練 AI 模型需要這麼大量的數據來回吞吐進行矩陣運作,也就代表著在硬體支援上,第一是會需要能一口氣進行大量的平行運算能力,第二是需要一次搬運就能儲存大量的資料來做運算。
平行運算能力這點顯而易見,我們指的是 GPU。*想複習的讀者可以參考我的上一篇文:NVIDIA在AI市場的霸權地位還能維持多久?全球AI硬體浪潮分析來襲
而後者,就是所謂的高頻寬記憶體(High Bandwidth Memory)簡稱 HBM。
對於電腦系統來說,記憶體的容量和頻寬是兩個很重要的效能指標。
容量代表著指的是記憶體可以儲存的資料量,容量越大,系統能夠同時處理的資料量就越多。
記憶體頻寬指的是記憶體在單位時間內可以傳輸的數據量,頻寬越高,處理器在讀取和寫入數據時的速度就越快,對於需要大量數據傳輸的應用尤為重要。
如果記憶體容量很大,但頻寬不足,就會在處理大量數據時出現瓶頸,因為數據無法快速讀取或寫入。反之,如果頻寬很高但容量不足,則無法充分利用高頻寬速度,因為無法儲存足夠的數據。
對於需要大量數據計算的應用(如圖形處理或 AI 數據分析),高頻寬和大容量的記憶體都是必須的。
在電腦硬體領域,「瓶頸」(Bottleneck)一詞經常作為一個會顯著影響系統效能的關鍵概念出現。想像一下一條由多車道合併為一條的高速公路,交通流量其實會受到最窄那條路的限制。
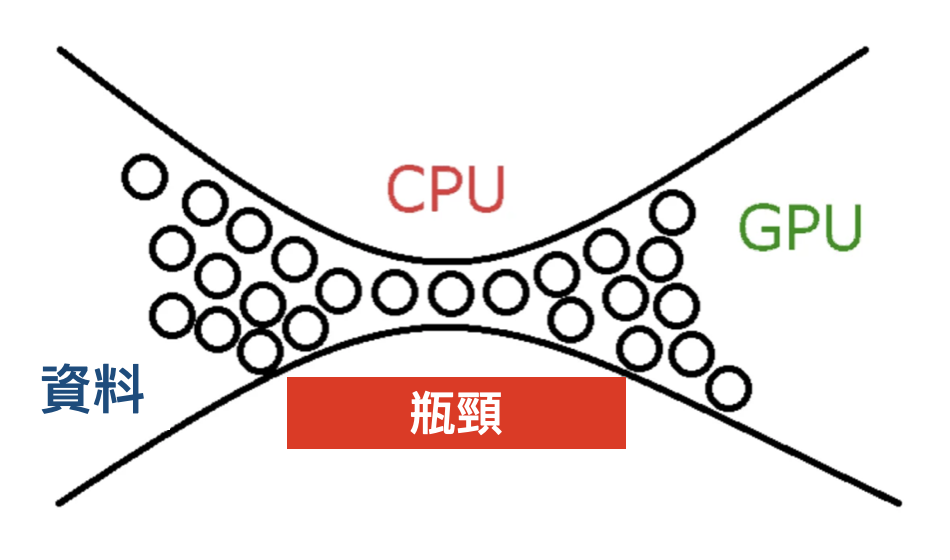
同樣的原理也適用於電腦系統。就算配備了超強大的 CPU 和高階顯卡,但假設我們開了一堆 App、還在各個 App 之間瘋狂切換,此時如果記憶體容量不足或速度緩慢,它就會成為整個系統的運算瓶頸,限制實際的運算效能。
由於 GPU 並不像 CPU 內部還有設計 L1、L2、L3 快取的階層式記憶體,因此記憶體頻寬這個議題自古以來對 GPU 而言始終非常重要。
可以參考以下 NVIDIA 銷量最高的 AI 顯示卡 H100,中間最大顆的是 GPU 運算單元,旁邊圍繞六顆 HBM 晶片。

或參考下圖 NVIDIA 最新發布的 GB200 顯示卡,由兩顆 B200 GPU 與自家的 Grace CPU 組成,HBM 就封裝在 B200 裡面。

HBM 的價格十分昂貴,是傳統 DRAM 的 2 – 3 倍。HBM 的價格也是 AI 晶片中佔比最高的部分(比台積電的晶圓製造服務還貴)。
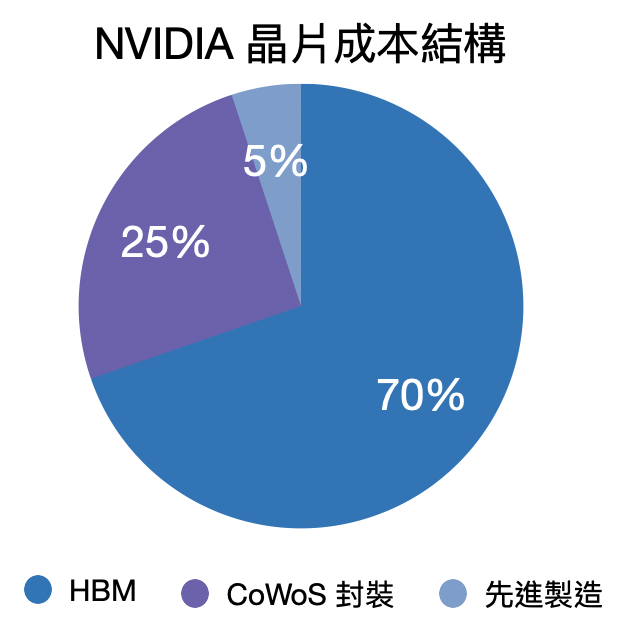
之前有消息拆解出一張 NVIDIA H100 並估計其成本接近 3000 美元,而其中佔比最高的就是 SK 海力士的 HBM 記憶體,總計高達 2000 美元左右,遠遠超過晶片製造和封裝,成為 GPU 製造成本中最大佔比的項目。
(不過一張 H100 的價格高達 2.5 – 3 萬美元,毛利高達近 90% 堪稱奢侈品等級的利潤)
這樣的情況下為什麼 AI 晶片還一定要使用 HBM 記憶體,不使用傳統的記憶體呢?
AI 晶片必須使用到 HBM 高頻寬記憶體的有主要以下幾個原因:
機器學習模型在訓練上需要龐大規模的數據吞吐能力,比如圖像、影片、文本等,都是驚人的複雜矩陣資料,因此需要在處理器和記憶體之間快速且大量地傳輸數據,同時也要控制散熱。
高頻寬 HBM 能夠滿足 AI 晶片在數據傳輸速率、運算效率、功耗和晶片空間利用等方面的需求,使得 AI 系統能夠在各種應用場景中表現出色,這也是為何 HBM 成為 AI 運算中不可或缺的內存技術的原因。
AI 運算能力高度仰賴 HBM 記憶體,有 AI 顯示卡就必定要有 HBM。
從 NVIDIA 的 H100 AI 顯示卡供不應求開始,也造就了 HBM 記憶體從去年到今年以來的訂單滿載,DRAM 廠甚至不惜以龐大代價轉換 DDR5 產能至 HBM。
現階段全球只有三家公司有生產 HBM 記憶體的能力:SK 海力士、三星與美光。2023 年的市占率分別是 54%、41% 與 5%。
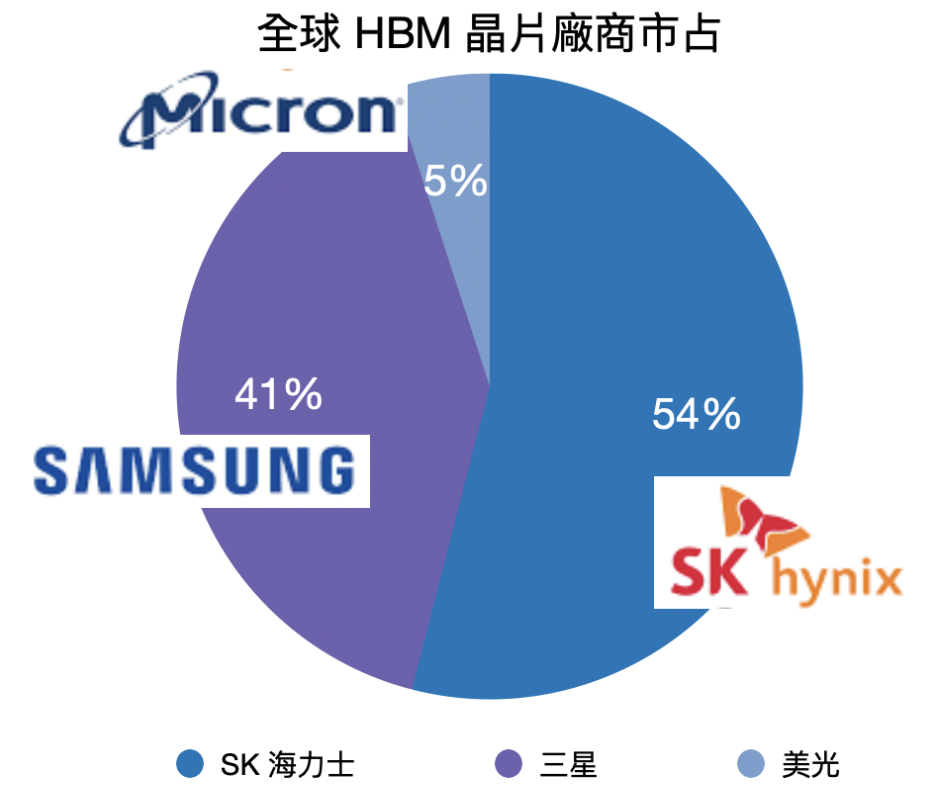
從數字上看來,第一大廠商 SK 海力士看似還沒有擁有壟斷性的市佔,但事實上 HBM 市場的第一大買家 NVIDIA 現階段使用的只有 SK 海力士的產品,近期才有其他品牌可能通過認證的消息。
HBM 廠商得通過買家 NVIDIA 與晶圓代工廠台積電的雙重認證,才能成為 NVIDIA 的供應商。
目前 NVIDIA 使用的都是 SK 海力士的第三代 HBM3 產品,直到今年美光才剛通過驗證,成為 SK 海力士以外的第二家可供應 NVIDIA 的 HBM 廠商。
三星至今還沒有通過 NVIDIA 與台積電的雙重認證,因此其 HBM 產品至今還未能在成熟的顯示卡產品上進行量產。
(今年 4 月有媒體報導傳出,三星有和 AMD 高達 30 億美元的訂單協議,供應 HBM 給 AMD 的 Instinct MI350 系列 AI 晶片上。不過但書是三星需要購買 AMD 的 GPU 以換取 HBM 產品的交易,具體交易數量和細節還不清楚)
HBM 與傳統記憶體有什麼區別?
不同的記憶體對應到不同的終端硬體產品:
- 高效能運算中心(HPC)- HBM / HMC
- 手機 – LPDDR4 / LPDDR5(6 代預計將於今年 Q3 釋出)
- 傳統伺服器 – DDR4 / DDR5
- 繪圖顯示卡 – GDDR5 / GDDR6
- 個人電腦 – DDR5 / LPDDR4

HBM 其實就是將多個 DDR 記憶體晶片堆疊起來,每一層控制在只有人類頭髮一半的厚度,再透過先進封裝和 GPU 封裝在一起,實現高儲存空間與高頻寬的目標。
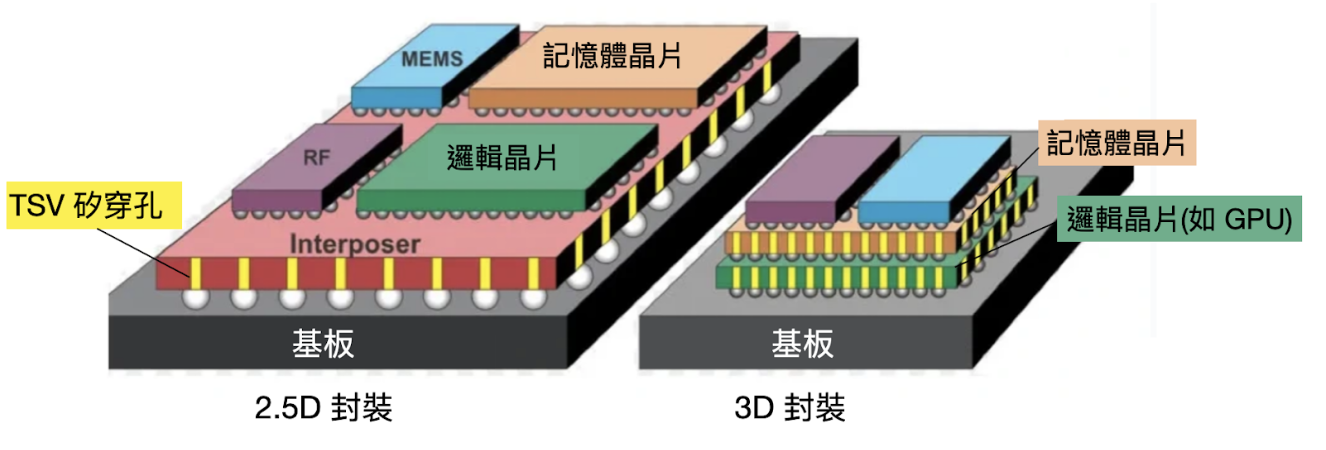
在 2.5D 封裝技術與 HBM 晶片還沒有被開發出來之前,記憶體都是採用 2D 傳統封裝技術。
CPU 與 GPU 等邏輯晶片與記憶體晶片,都是透過引線連接到下方的基板上,再透過基板實現邏輯運算與儲存之間的通訊,如下圖所示:
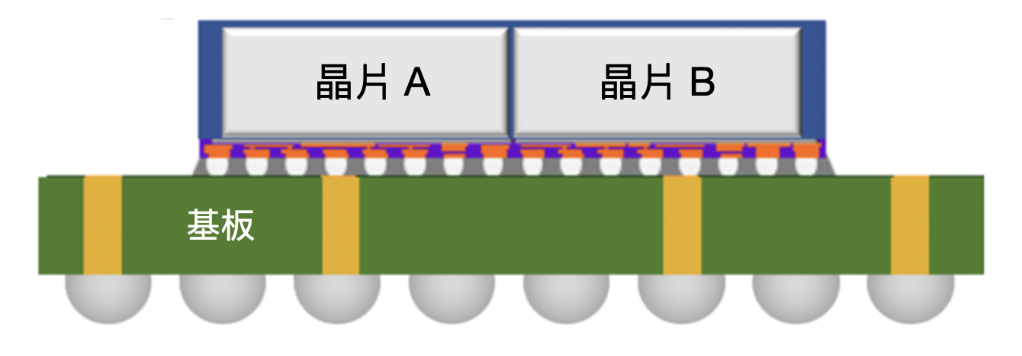
但如果晶片變得更多,除了會導致佔用印刷電路板上的大量空間之外,還意味著必須鋪設很長的電線才能到達 GPU,也需要更大的變壓器。
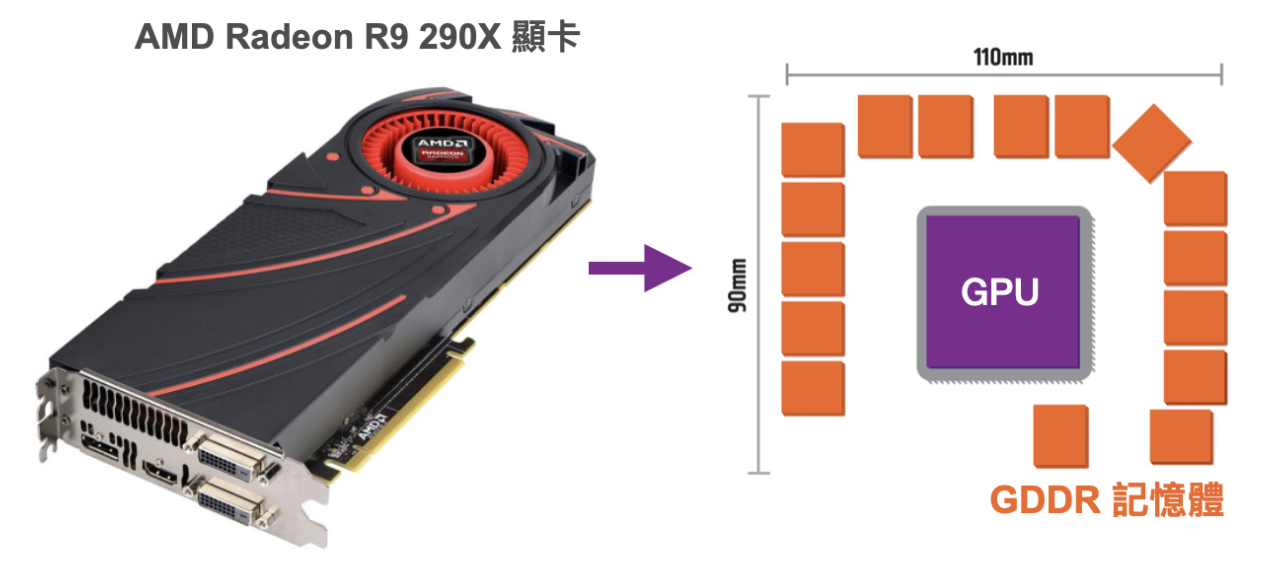
比如下方 AMD 顯示卡 Radeon R9 290X 的佈局,GDDR 記憶體晶片使用了大量的空間以及電線得拉很長,才能觸及到中間的 GPU。
那如果是在 HBM 的世界呢?
到了 2.5D 堆疊晶片的時代,透過堆疊四個記憶體晶片,記憶體可以更靠近 GPU,從而大大縮短了電線長度,達到更短的傳輸路徑、更高速且耗能更低。
四塊堆疊在一起的 HBM Dram 裸片,與最下面一顆作為集線器用的邏輯運算晶片,這五塊晶片都透過「矽穿孔」技術來互相連接導電。
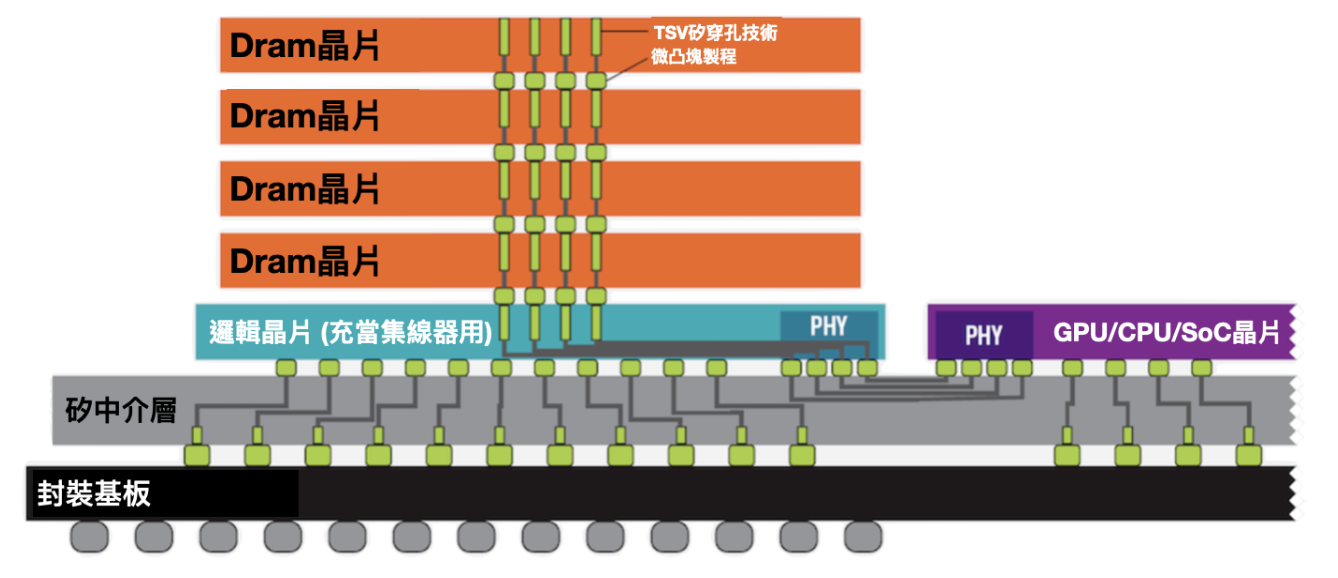
所謂的矽穿孔,就是直接在矽晶圓上穿多個孔,孔的大小只有微米等級(差不多就是細菌大小),並使用金屬物質填充進孔裡來進行導電連接,這樣的打洞技術就稱為「矽穿孔」(TSV, Through Silicon Via)。
每層也使用微小的凸塊直接連接到下一層,各層互連且電線不必走得太遠就能到達 GPU。矽穿孔技術代替了傳統的引線,可以有效降低功耗,並使裸片堆疊,提升儲存頻寬。
接下來再把堆疊好的 HBM 晶片與圖片中的 GPU 核心運算單元再封裝到一層叫矽中介層(Interposer)的介質上,矽中介層上同樣會有提前蝕刻好的矽穿孔,讓 HBM 與 GPU 運算單元也可以透過矽穿孔來連接,不用引線和基板,再一次降低功耗並提升頻寬速度。
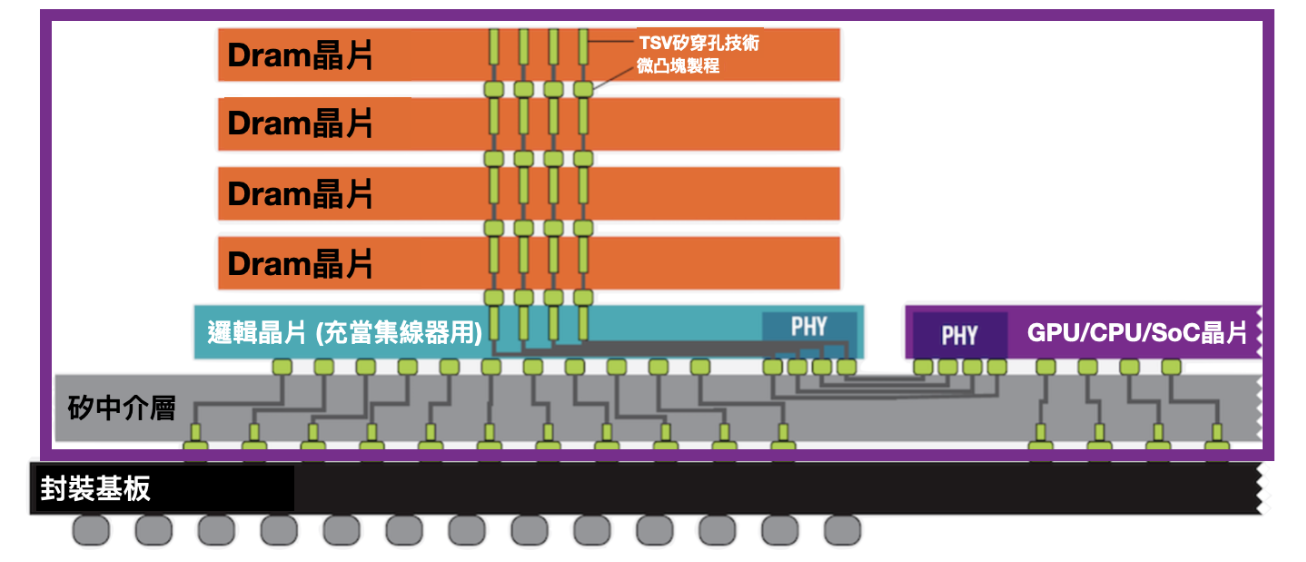
最後把封裝好的矽中介層連接到基板上就完成封裝啦!
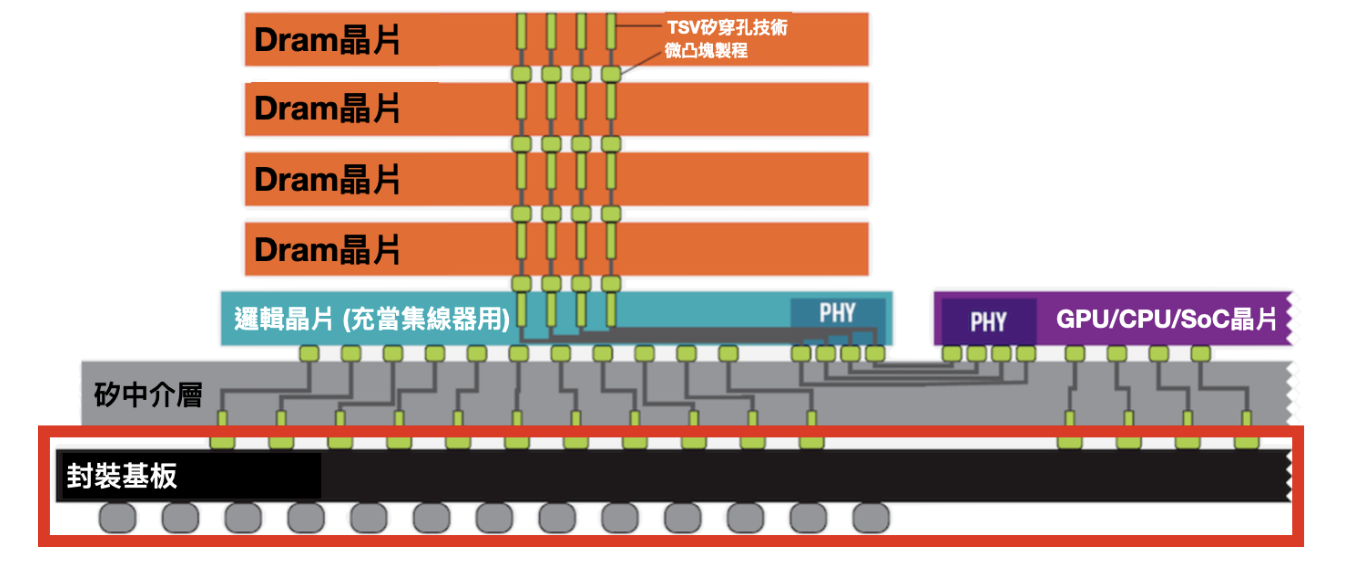
2D 和 2.5D 之間的區別在於,傳統 2D 封裝都是在基板這個平面上。但透過矽穿孔跟矽中介層,封裝開始堆疊在一起不存在同一個平面上,因此稱為 2.5D 封裝。
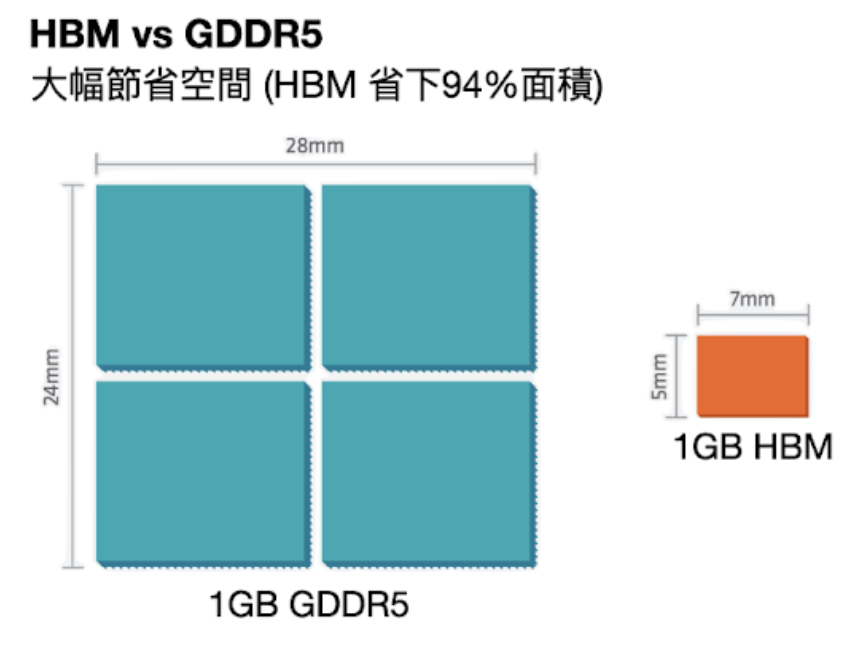
將晶片都疊起來後,直接結果就是省下大量的面積,晶片間接觸介面也變得更寬,下方連接的接點數量遠遠多於傳統記憶體連接到 CPU 的線路數量。因此,與傳統記憶體技術相比,HBM 的頻寬更高、功耗更低、尺寸更小。
從 2.5D 到 3D 封裝的話,就是更進一步把記憶體晶片堆疊在 GPU 上面。
平面一般常見的記憶體有 2 / 4 / 6 / 8 層四種立體堆疊方式,目前最多堆疊到 12 層。
怎麼聽起來很簡單,只是把晶片堆疊在一起而已?
首先是堆疊層數越多,記憶體就必須做的更薄,研磨變得更精細化且更困難。同時矽穿孔本身也得研究具體鑽孔的大小、灌入孔當中需要使用何種金屬或是聚合物、電損耗、互聯金屬的可靠度,與金屬/異質晶片/基板之間的負熱膨脹係數差異、持久性等等議題。
接著是晶圓堆疊的精準度,由於 2.5D 或 3D 堆疊具體實現的方式,是在晶圓處理階段,也就是在堆疊並切割的時候就必須精準地對齊只有微米等級大小的矽穿孔進行切割,才能保證晶片相互之間成功導電。
最後的最後,還有晶片被壓縮放置地更緊密的散熱問題,除了也是封裝上的難題。
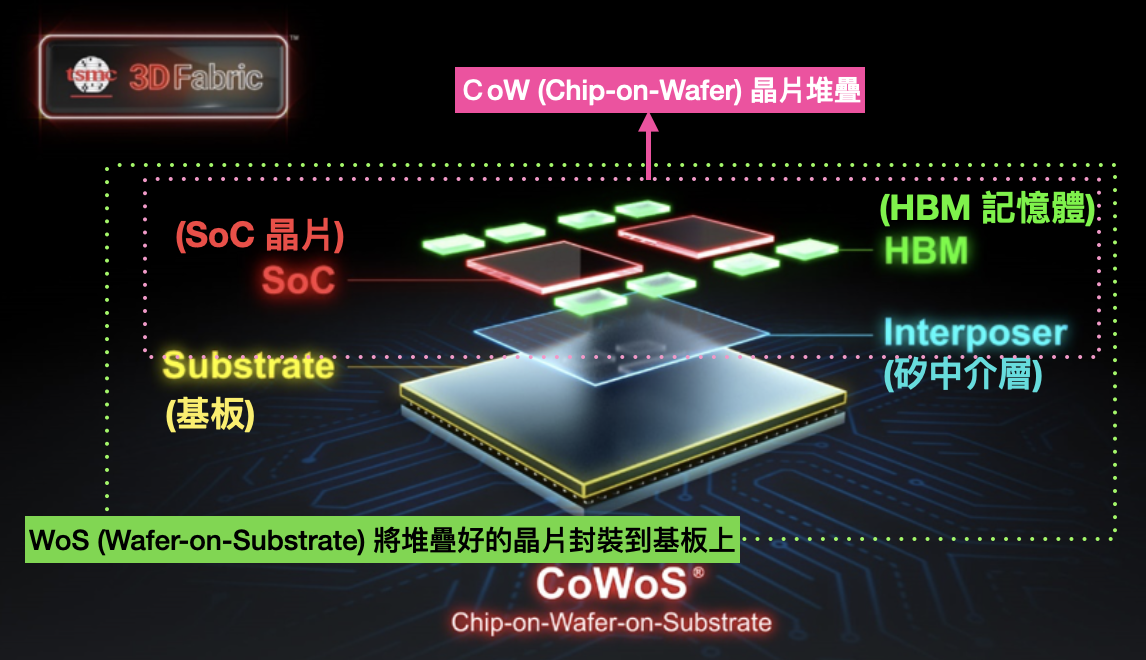
HBM 廠商做出 HBM 之後,還需要靠先進封裝技術把 HBM 與其他異質晶片封裝在一起。這時候就需要台積電的 CoWoS 技術出場啦!
台積電的 CoWoS 技術其實就是分成 CoW + WoS。
CoW(Chip-on-Wafer)指的是透過矽穿孔技術,將裸晶與矽中介層連接在一起。WoS(Wafer-on-Substrate)則是把堆疊好的晶片與矽中介層再透過微凸塊連接到基板的過程。
為什麼 HBM 晶片現在才爆紅?
HBM 既然效能如此強大、擁有這麼多優點,怎麼會拖到現在才產能吃緊呢?
HBM 作為行之有年但乏人問津的冷門技術,提到第一個搭配 GPU 推出它的人大家可能會很驚訝,就是我們耳熟能詳的遊戲好夥伴 AMD。
如果說 Intel 是 CPU 的龍頭,NVIDIA 是 GPU 顯示卡的龍頭,AMD 原先也只是一家被 Intel 壓著打的僅做 CPU 市場中的萬年老二。
但在 2006 年 AMD 斥資做了一個大膽的選擇:以 54 億美元天價收購了當時的第二名 GPU 廠商 ATI,從此成為業內唯一一家能夠同時提供高效能 CPU 與 GPU 的公司。

GPU 功能單一但可以進行高效能平行運算,CPU 是應對各類型的通用運算但單核心性能提升有限,收購完成 ATi 的 AMD 此時描繪了一個美好的願景--如果我們把 CPU 與 GPU 兩種不同架構體系的產品整合在一起,做出一款「APU 融合處理器」呢?那絕對是會力壓 Intel 與 NVIDIA 的革命性產品。

當然接下來的故事我們都知道了,理想很豐滿,現實卻總是很骨感。斥資收購 ATi 後的 AMD 開始面臨內部財務狀況危機,CPU 和 GPU 雙端市場也都競爭不過各自業內原先的老大,APU 處理器的確後續發表了好幾代但效能有限。
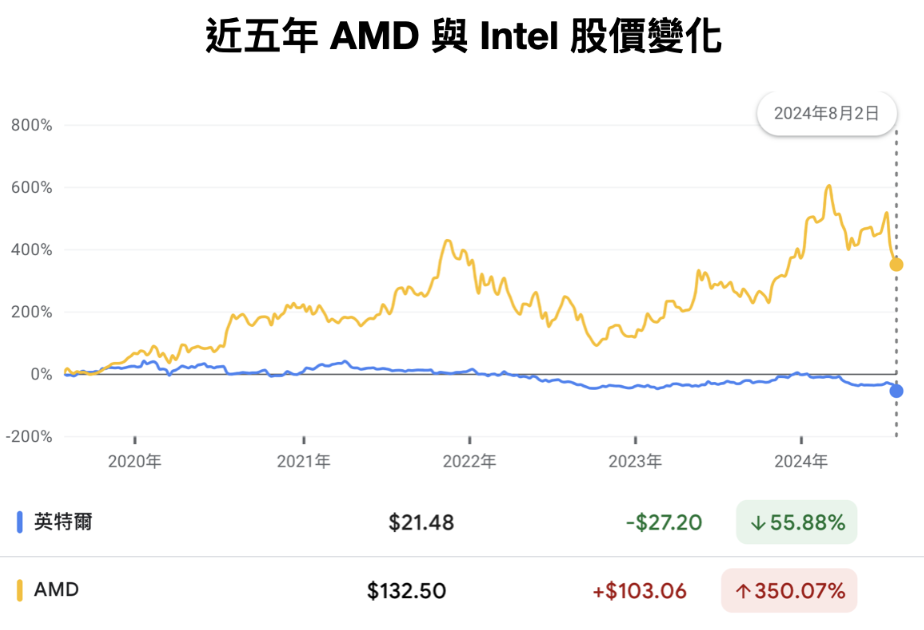
現任 CEO 蘇媽在 2014 年剛加入 AMD 成為執行長的時候,AMD 股價只剩下 1.61 美元、負債超過 20 億美元,全球裁員且公司謠傳差點就要破產,營運前景風雨飄搖。
十分勵志的是這十年間在蘇媽的帶領下成功轉型,市值突破千億美金,市值成功超越了以往的老大哥 Intel。
但當年還在雄心壯志的 AMD 繼續做了一個顛覆半導體業界的決策:著手研發 HBM。
2009 年是電腦遊戲與網頁技術爆發的階段,有了 APU 這個弘大願景,加上 APU 其實就是異質運算的概念(在同一套系統中透過適當的分配,使 CPU 與 GPU 各自執行對應的工作,藉此進一步提升系統整體的運算效率)
AMD 決定聯合多位業內大佬,包括記憶體龍頭 SK 海力士、可以做出矽中介層的聯電,與可以負責先進封裝測試的日月光和 Amkor,開始研發 HBM 的初代技術。
HBM 的初步構想如下:整張顯卡的總功耗是有限的,更多的記憶體會擠壓到核心運算單元的功耗,進一步影響顯卡的效能。要怎麼能在提升顯卡容量的同時,維持低功耗與小體積呢?
歷經多年的研發投入後,在 2013 年,AMD 終於成功和 SK 海力士開發了全世界第一款 HBM,後面也終於成功在 2015 年推出第一款搭載了 HBM 晶片的顯示卡 Radeon R9 Fury X。

但隨後,AMD 便發現搭載 HBM 的顯示卡成本太高,但對於遊戲效能的提升卻有限。由於 HBM 的製程難度高、成本也貴,Radeon R9 Fury X 總共只有搭載 4 顆 1 GB 的 HBM 在內,也就共 4GB。
電腦有自己的記憶體,顯示卡也擁有自己獨立的記憶體,就是為了儲存 GPU 已經處理過或即將讀取的渲染數據,如果容量不夠照樣會出現鋸齒狀的畫面。
一般來說要跑 1080P 解析度的遊戲,會需要 6 – 8 GB 左右的顯示卡記憶體。但 AMD 這堂堂一張旗艦顯卡卻只有 4GB 的容量,就算頻寬速度再快,容量大縮小也直接讓 HBM 失去了實際價值。
由於一開始是以遊戲目的出發,HBM 的高頻寬優勢在遊戲算力無法彌補 AMD 與 Nvidia 在遊戲 GPU 上的性能差異,無法為 AMD 帶來顯著的效能優勢,礙於成本太高,AMD 顯示卡產品線後續也走回 GDDR6,畢竟當初 AMD 推動 HBM 顯卡的初衷是應用在自己的遊戲顯示卡上。
難道 HBM 這項技術就這樣沒了嗎?
AMD 不要的 HBM,NVIDIA 要
NVIDA 此時說了:AMD 不要,我要。
NVIDIA 敏銳地嗅到 HBM 的重要性,畢竟 NVIDIA 從 2006 年就一直在不惜成本地推動 CUDA 運算平台,想讓 GPU 轉型成通用且高效能運算晶片,與 HBM 可以拿來解鎖 GPU 超強算力並拉高儲存空間與頻寬的目標不謀而合。
此時在 HBM 市場上的領先者也不是 SK 海力士,而是記憶體龍頭三星。在 AMD 與 SK 海力士推出第一代 HBM 後,NVIDIA 也聯合了三星投入第二代 HBM 的研發。
2016 年前後也正好碰上第一次 AI 浪潮,因此在 AMD 於 2015 年放棄了 HBM 後,隔年 NVIDIA 使用台積電 CoWoS 2.5D 封裝技術加上三星的 HBM2,推出了第一張 AI 顯示卡 Tesla P100,成為歷代最強的 GPU 加速器。

此時 SK 海力士因為被 AMD 放棄了 HBM 技術,直接在 HBM 第二代的標準上落後三星一年多的時間。
若繼續按照這個情況下去,三星不但 HBM 技術遙遙領先、還擁有最大的 HBM 客戶 NVIDIA,SK 海力士根本沒有跟上的可能。
然而三星自己卻犯了一個致命性的錯誤,由於 HBM 的生產成本過高、市場需求低,三星決定在 2019 年解散了 HBM 研發團隊,導致從 HBM 第三代開始技術上便落後於 SK 海力士,最終導致在 AI 浪潮落後的結果。
三星與 SK 海力士,誰的 HBM 更強?
三星和 SK 海力士的 HBM 技術有差異嗎?為什麼作為記憶體龍頭,三星現在會落後於老二 SK 海力士?三星有可能會在近期就立即追上 SK 海力士的腳步嗎?
三星在 HBM 技術上落後的原因,除了為了縮減人力成本就貿然解散 HBM 團隊,還有一個原因是因為它使用的 HBM 生產方式,與 SK 海力士所採用的技術也完全不同。
三星的 HBM 採用的是 TC-NCF 製造技術,也是 SK 海力士最開始研發出來的 HBM 技術。
NCF 是一種非導電薄膜,通常由聚合物材料製成,具有良好的粘附性和熱穩定性,能有效填充晶片之間的空隙。
應用在 HBM 的製造時,就是在每次堆疊晶片的時候,在各層記憶體裸晶之間的空隙填充 NCF 非導電黏合膜,將晶片彼此隔離起來、保護連接點避免受到衝擊,再將塗佈有 NCF 的晶片加熱,使其固化並形成穩固的連接層,最後將多層晶片進行壓合。
可以想像成熨斗一樣--把絕緣膜疊在晶片上、再把下一顆晶片疊上去再用 TC 黏合機把薄膜融化把晶片接合在一起。
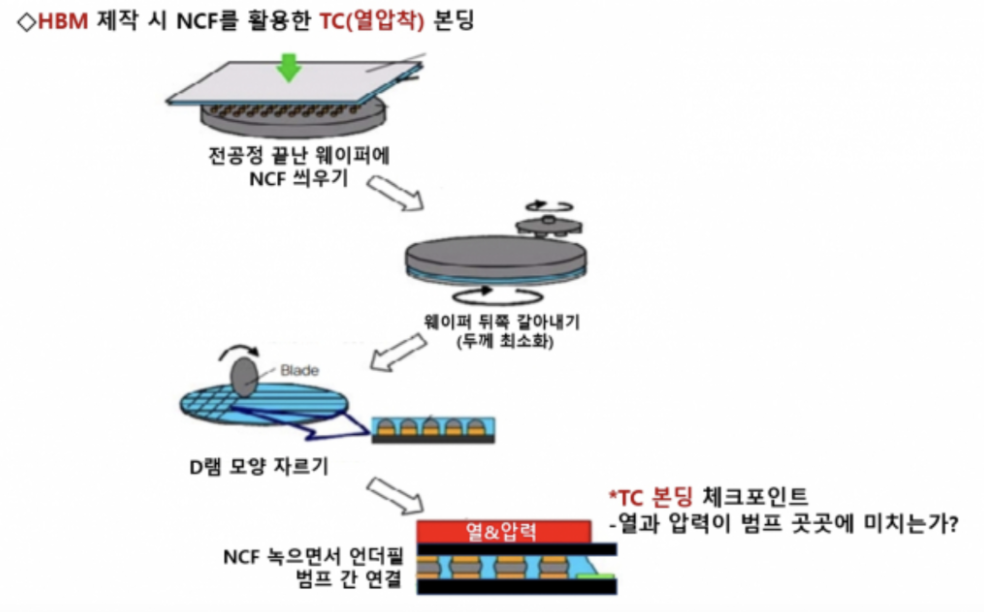
只要在製造時把 NCF 材料的厚度變得越來越薄,堆疊晶片的空間就可以越來越小,還可以在晶片層數增加、晶片厚度變小的時候,避免晶片發生翹曲。三星和美光主要都使用這個方案。
但 SK 海力士則率先放棄了 TC-NCF,鍥而不捨地研發新技術,最後在 2019 年改為採取另一種工藝製造技術:MR-MUF。
這個投入非常的關鍵,因為在 2015 年 – 2022 年 HBM 乏人問津的期間,連三星都在 2019 年裁掉了 HBM 的研發部門,SK 海力士卻在同年推出了新技術,徹底改變了 HBM 市場的未來。
(當年也是 SK 海力士最早推出 TC-NCF 技術,三星在 HBM 上面就主打一個躺平)
如果說 NCF 技術是把晶片和 NCF 材料一層一層填充上去做堆疊,MR-MUF 則是先要將堆疊的晶片正確排列好,確保它們之間的接口接觸良好,再把位於晶片基座的凸塊同時融化以進行焊接,最後把具有散熱效果的化合物加熱後流入晶片間填充起來保護晶片。
可以想像成在烤箱中烘烤晶片、把晶片疊好後一次性加熱黏合劑來黏合所有晶片。
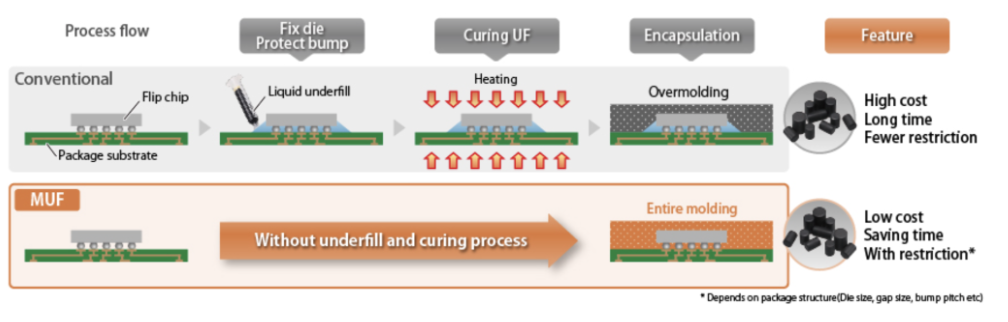
TC-NCF 技術看似會讓晶片比較不會發生翹曲問題、適合堆疊更高的晶片,但隨著晶片堆疊的層數越來越多、NCF 材料厚度變得更薄,整體製造過程會變得更加複雜,與黏合材料相關的製造問題發生地會更加頻繁,想像每一次堆疊機器物理設定都會有些微的誤差,累積起來的總誤差就可能導致良率下降。
MR-MUF 則省去了逐層覆蓋的步驟,可以一口氣對垂直堆疊在一起的晶片進行加熱和互聯,比起 TC-NCF 製程的穩定性與良率更高。
總結而言,TC-NCF 技術(想像成層層疊上去的熨斗)的優缺點如下:
*優點
- 逐層堆疊每個單獨的晶片上去,晶片彎曲的翹曲現象會比較少,晶片之間未對準的問題也會比較少
- 只要把薄膜變薄,就可以輕易縮小晶片之間的間距,在有限空間下大量擴展 HBM 堆積高度
*缺點
- 但 NCF 材料的物理性能變化較大、很難控制穩定度
- 薄膜融化時,晶片可能會出現滑動就黏在一起
- 薄膜如果沒能均勻填充晶片之間的空隙,就會出現散熱不佳的問題
- 用 TC 機黏合時,必須把晶圓的各層進行研磨,只要研磨的厚度不均勻,則被施加到晶片個部分的壓力就會不同,導致缺陷率上升
MR-MUF (想像成一次性烤箱烤三明治)的優缺點則是:
*優點
- 直接一口氣將所有晶片對齊並堆疊在一起,再把晶片焊接在一起、並注入散熱樹脂,同時進行底部填充和成型工藝
- 把散熱樹脂用作間隙填充材料,導熱率比 TC-NCF 中的非導電薄膜高得多,對於 GPU 這種高功耗晶片的散熱管理非常重要
- 除了散熱效果更好,生產效率和良率也大幅提高,SK 高層表示成功把生產率提高了 3 倍、散熱度提升 2.5 倍
*缺點
- 在高溫焊接的過程中,晶片有可能會因為暴露在高溫下而產生彎曲的問題,焊接的凸塊也有可能因為乾燥而破裂
- 晶片要事先對準,在堆疊層數更高的情況下會比較困難,容易不小心發生短路
- 用來散熱填充的樹脂材料黏性很高,在晶片堆疊層數更高、凸塊間距變小的情況下很難均勻地填充好

可以看出以上 MR-MUF 要能成功,靠的也都是產線經驗累積出來的 know-how,背後也是好幾年的肝堆出來的技術領先。
現階段在量產上,三星的 NCF 技術遠不如 SK 海力士的 MR-MUF 技術來得穩定。三星的第三代 HBM 生產良率僅為10% – 20%,但 SK 海力士的 HBM 良率則高達 60% – 70%。
加上高功耗與散熱不佳的問題,三星的 HBM 至今仍無法通過 NVIDIA 與台積電的驗證實現量產。
不過,三星副總裁也在先前表示,在最多 8 個堆疊時,MR-MUF的生產效率比TC-NCF 更高,但一旦堆疊達到 12 個或以上,後者將具有更多優勢。
既然已經在 MR-MUF 上落後了,等 HBM4 推出的時候,三星或許還有機會能趕超 SK 海力士,因此三星也始終不肯放棄 NCF 轉向 MR-MUF,因為背後需要的機台投資與時間成本實在太高,高層肯定會有疑慮,假設等到量產了,AI 需求如果消失了怎麼辦,面臨高風險決策,三星高層疑慮其實很多。
然而,近期已有媒體披露三星已經下單了用於 MUF 技術的製造設備與材料,很有可能三星會同時採用 NCF 與 MR-MUF 進行生產,但要能使用 MUF 技術進行量產最快也應該會等到明年。
畢竟目前生產 HBM 的週期就已經是半年,三星要採用新設備與新技術,加上測試時間,大概率會需要一年左右。
近期三星也在 2024 年第二季財報電話會議上表示,第五代 8 層 HBM3E 產品將於今年第三季實現量產(不過使用的還會是 NCF 技術)。
說完了 AMD 從率先帶領大佬們研發出 HBM、到蘇媽上任後為了節省成本在遊戲顯卡上停用 HBM,到 NVIDIA 的先見之明大力擁抱 HBM,到三星與 SK 海力士之間的策略爭鬥,與 SK 海力士從老二變老大的翻身之路……
相信大家看到這裏,對於科技技術瞬息萬變,與商場戰略上牽一髮便足以撼動整間公司未來十年命運的結果,有了更深一層的體悟。(只能說看一間企業的前景,核心還是得看企業文化與管理階層是否具有洞見)
*Lynn 按曰:這整個故事,首先可以看出 AMD 蘇媽與 NVIDIA 黃仁勛在前瞻技術洞見上的差異。再來是 SK 海力士--竟然可以從 2013 -2022 年近十年的光陰一直在大手筆投入 HBM 的研發(要不是剛好有出現 AI GPU 浪潮,可能等待的時間又會更久),當同行在記憶體產業不景氣、都裁撤部門放棄這項技術的時候,SK 海力士還在持續把它當核心技術在耗費心血,可見高層洞見之深、其心可狠,簡直大發… respect.
接著,讓我們來談談台積電。
乏人問津的 HBM,乏人問津的 CoWoS
談到晶片產業,最廣為人知的概念莫過於 Intel 共同創辦人摩爾在 1964 年提出的摩爾定律(Moore’s Law):在同樣面積的 IC 晶片上可容納的電晶體數目,每 18 至 24 個月就會增加一倍。
台積電在 2022 年也已經推出領先業界的 3 奈米技術,但畢竟電晶體大小仍然有物理限制。
考量到這點,台積電才因此在 15 年前便推出 CoWoS 技術作為未來必定會遇到的摩爾定律的解方。除了藉由縮小電晶體之外,還可以用 3D 堆疊的方式提升單位面積的電晶體密度。
然而在 2009 年當台積電決定斥資一億美金、耗費 400 位工程師,終於研發出先進封裝技術 CoWoS 出來時,諷刺的是卻一個客戶都沒有。
只有小眾 FPGA 晶片廠商 Xilinx 願意採購,但一個月只要 50 片,相較於高昂的研發成本,銷售量卻少到可憐,也讓 CoWoS 當場變成一個業內大笑話。
由於 CoWoS 的成本太貴,後續台積電又在成本考量的基礎上推出了同樣是先進封裝技術的 InFO。
InFO 技術使用聚醯亞胺(polyamide)代替 CoWoS 中的矽中介層,直接降低了成本和封裝高度(畢竟矽中介層就佔了 CoWoS 成本的 50%)。蘋果最後採用並大規模生產的消費性電子手機晶片也是使用 InFO 封裝技術,擁有高效能與低功耗的特性。
同樣,接下來的故事我們也都已經知道了,2016 年的 AI 浪潮後,AI 再度因為訓練方式的局限而陷入很長一段時間的瓶頸,直到 2022 年底橫空出世的 ChatGPT 才出現突破,
然而在 ChatGPT 出現之前,無論是 HBM 還是 CoWoS,在 2022 年底在 NVIDIA GPU 因為 AI 浪潮開始紅起來之前都屬於冷門產品—— 單論遊戲顯示卡需要的性能,根本不需要 HBM,而且 HBM 生產週期較 DDR5 長,從投片、產出到封裝完成需要長達半年以上的時間,成本也遠高於普通記憶體晶片,以一台 AI 伺服器的成本中,佔比高達 9%。
但在 AI 浪潮開始並需要硬體基礎建設之後,自此,台積電的 CoWoS 2.5D 封裝技術 + SK海力士的 HBM 晶片,就是 NVIDIA AI 顯示卡的標準配置。

黃金三角誕生:AI GPU + CoWoS + HBM
在 AI 時代,一切都不一樣了。
NVIDIA 領軍的 AI 浪潮下,CoWoS 需求激增三倍,驅使台積電全力擴充 CoWoS 產能。NVIDIA 今年推出的旗艦產品包括 B100 或 H200 ,記憶體規格皆為 SK 海力士最新的 HBM3e 產品。
由於 AI 需求高漲,NVIDIA 與其他品牌 GPU 或 ASIC 供不應求,CoWoS 和 HBM 都成為了 GPU 的供應瓶頸,從乏人問津的冷門產線變成供不應求的次世代技術。
「NVIDIA + 台積電 CoWoS + 南韓 HBM 記憶體」可以說是黃金三角的綁定關係,缺乏任一個關係就不存在 AI GPU,不存在 AI 產業發展。
(但同時這並不是說 CPU 變得不重要了,CPU 依然重要,但 AI 時代 HPC 資料中心對於 CPU 的需求是過去的兩倍)
但這也顯示了 NVIDIA 的供貨瓶頸其實就卡在台積電的 CoWoS 與 HBM 晶片產能,或甚至是後兩者互相影響。NVIDIA 只是負責 IC 設計的無廠半導體公司,如果 HBM 晶片供應不夠、台積電的 CoWoS 也沒有貨可以塞;或是 HBM 晶片供應充足,但台積電 CoWoS 產能被其他廠商訂單吃掉部分。
你可能會想問:HBM 可以理解是 SK 海力士最早投入,也因此是該公司最成熟的技術,那為什麼一定 2.5D 封裝就一定要使用台積電的 CoWoS 技術呢?
由於 2.5D 封裝技術是由各家廠商自己研發,彼此間的技術細節差異很大。這些細節差異就會導致即便使用的是 NVIDIA 給出來的同一張 H100 設計圖,只要想拿到台積電以外的封裝廠也無法做出相同的產品或維持相同成本,很難做品質管控,或是出問題時也難以把責任歸咎於特定一方,管控上非常複雜。
比如堆疊晶片的時候,會需要晶片與晶片之間完全貼合,對於晶片表面平整度的要求非常高,很考驗產線的切割工藝;或是 TSV 矽穿孔這邊也是台積電來執行,那麼矽穿孔的孔該多大、中間灌入的金屬選什麼材質等等…
剛我們提到 CoWoS 又分成 CoW 與 WoS,上面我們講的核心挑戰都是 CoW 這邊會遇到的,因此 WoS 的部分還可以外包給其他下游封裝廠商,但 CoW 的訂單絕對是只有台積電能接。
也不僅僅是 NVIDIA,AMD、博通、微軟等廠商也通通都需要台積電的 CoWoS 技術和 HBM 記憶體。
如何深刻理解 AI 硬體的 iPhone Moment
我們來思考黃仁勳在 2023 年 3 月發表的:此刻是 AI 的 iPhone Moment(The iPhone Moment of AI)背後潛藏著什麼意義。
NVIDIA 的成功靠著天時地利與人和,要不是:
- 有 AMD 一開始找 SK 海力士研發 HBM 且 SK 海力士後續近十年的苦苦支撐
- 台積電 15 年前便自行研發並具備的 CoWoS 技術
- NVIDIA 早早地佈局無人看好的 CUDA 運算平台嘗試解鎖 GPU 的通用運算功能
要能實現高效能 AI 顯示卡根本是不可能的事情,堪稱冷板凳球員的絕地反攻。
iPhone 的出現並不是賈伯斯憑空的發明,而是把市場上既有的技術打包在一起,包括螢幕觸控技術、App Store 商店一鍵下載應用、德國百靈的工業設計外觀等等,將市場上既有的產品取其所長結合在一起,推出第一台真正意義上的智慧型手機。

什麼是 iPhone Moment?就是把市面上既有的前端技術,透過企業經營家的長遠洞見、透過多年的潛心研發,透過最後一步命運般地關聯,在某一刻集合在一起,爆發出電腦發明或是智慧型手機誕生的璀璨的一刻。
AI 就是這個時代的 iPhone,但 iPhone 的誕生是醞釀與積累已久的厚積薄發。半導體技術也是。
這才是真正意義地重新定義,並深刻地理解,何謂半導體產業 AI 的 iPhone Moment。
翻轉台灣與南韓經濟命脈的 AI GPU
進一步而言,NVIDIA 背後乘載著除了 AI 創新的硬體基石,更是台灣與南韓兩國的經濟發展重心。
誠如半導體對於台灣的重要性,半導體產業同樣是南韓最重要的經濟支柱,其中又以記憶體晶片的重要性最高。
這個數字有多誇張呢?先說印象中作為半導體聚落第一大國的台灣,半導體佔 GDP 佔比為多少:約 13%。
那南韓呢?答案是:半導體產業佔比高達南韓 GDP 的 20%,記憶體晶片又佔比南韓出口總值的 63.8%(2022 年數據)。
南韓國家智庫於 2023 年發表報告稱,南韓只要半導體出口值每下降 10% 就會導致 GDP 下降 0.78%。
南韓近年在晶圓代工的市場逐漸被台灣取代後,記憶體變成最核心的晶片業務。
然而不像台灣的晶圓代工與封裝廠商可以有多種不同細分類別的客戶類型,記憶體晶片的類型單一且產量大,只要一點點的供需失衡,很容易就會產生價格極端急上急下的問題,廠商也很難有穩定收入與盈利。
2022 年以來,因疫情驅動的消費型電子產品需求銳減,加上俄烏戰爭、通膨升息、物價飆整等經濟局勢不穩,硬體換機需求疲弱,導致記憶體供給過剩、晶片銷售持續低迷,讓南韓經濟發展上陷入嚴重的不景氣,也因此在 2022 年人均 GDP 終於被台灣超越。
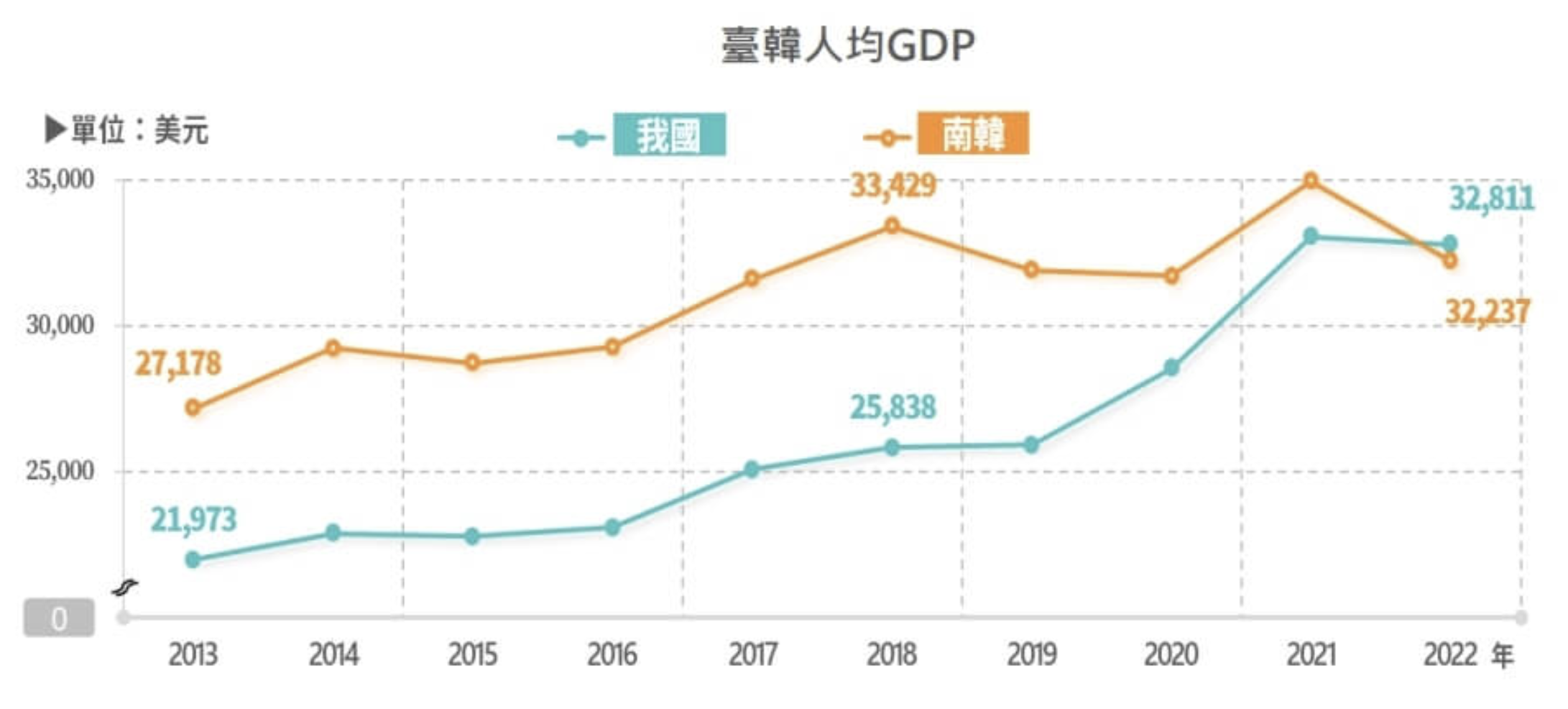
從 NVIDIA 作為 IC 設計、SK 海力士與三星的 HBM 記憶體、到台積電的晶圓代工生產和 CoWoS 先進 2.5D/3D 封裝技術,也是把美國矽谷軟體革新,和台灣半導體與南韓半導體,三國最重要的核心產業與 GDP 經濟發展未來緊密地綁定在一起。
半導體晶片出貨是否已經冷卻?不
最近半導體股票出現大幅下殺,許多分析師都在問大廠的 CAPEX 支出是否已經到頭?
早在今年 1 月,Mark Zuckerberg 便宣布 Meta 預計會在 2024 年年底前購買約 35 萬個 Nvidia H100 GPU,直到 2024 年底 Meta 估計將擁有約 60 萬枚的晶片。
若單顆 NVIDIA H100 的成本約在 3 萬美金,總計花費已經來到了 180 億美金(約 5,868 億台幣),這種程度已經在規模上已經超過其他公司所擁有的算力,
在近期的 Meta 的 2024 Q2 財報會議上,Meta 財務長未公佈具體數字,但預測 2025 年的資本支出將會有顯著成長(significant capital expenditures growth),以持續投入 AI 研究與產品發展。
微軟也在 Q2 財報會議中表示,截至其財年的 6 月 30 日 Q4 的資本支出成長高達 77.6%,來到了 190 億美元,其中基本上都是雲端和 AI 的相關支出。
記憶體三大廠--SK 海力士、三星與美光的 HBM 到明年與後年的全部產能已經都被預訂光。短期內記憶體也會呈現供不應求的態勢。
根據 Business Korea 報導,SK 海力士將深化與台積電與 NVIDIA 之間的合作,並在今年 9 月的台灣國際半導體展(Semicon Taiwan)上宣布三家公司更緊密的合作計畫以催生次世代 HBM 技術。SK 海力士和台積電也已同意合作研發並生產 HBM4,並將於 2026 年實現量產。
近期的全球股災是否代表半導體市場熱已經退燒?
我的答案是:不是的。就算短期波動劇烈,長期而言,如果說投資美國科技股大盤,等同於投資美國科技業的未來前景與國力,投資 NVIDIA 與 AI GPU 的成長,也相當於押注了台灣與南韓的未來。
距離 AI 自 2022 年底出現 ChatGPT,整體的爆發式成長還不到兩年,AI 演算法論文正以「每週」的頻率在更新,每一次出來的算法都更強更精準,軟體應用面還需要時間去發展與普及,但算力一定要準備好。
現在反而是各家在做算力軍備競賽的階段,台灣也難得碰上這項多項巧合共同發生下的產業機會。
許多人也在質疑 AI 的變現能力,但現在世界最優秀的人才都聚集在 AI 產業,絞盡腦汁研發商業應用,只要出現幾個破壞式創新將可能有龐大的商機,Lynn 自己是持續肯定人類的創新能力,而 AI 絕對是創新發生機率最高的選項。
與讀者聊聊 Time~
這篇文章長達 1 萬 2 千多字。

很早就有動念寫 HBM 和 CoWoS 的念頭,但從查資料到撰寫完畢,斷斷續續也拖了快兩個月,實際撰寫耗費長達三四十個小時以上。在 AI 時代,或許很多創作內容都已經沒有人類的空間,也可以直接丟問題讓 GPT 幫忙寫完就行
但這 1.2 萬字的內容,全部是我看著資料沈澱,最終一字一句敲下來的。AI 或許可以告訴我們單一問題的答案,但人類所擁有的價值,還是得透過事實的脈絡中找到變動的真理,並以此作為信仰與價值觀的依據。
在研究 HBM 的過程中,研究各個企業發展沿革的過程中,雖然寫的是理工相關科普,我卻彷彿感覺 AI 的出現是一種時也,運也,命也般的安排。很幸運能生在這個時代,見證這奇蹟般的一刻。
如果你喜歡 Lynn 的文章,喜歡寫點科普的精神,歡迎以贊助行動支持網站營運喔!
也可以追蹤寫點科普IG kopuchat 與FB粉絲專頁 寫點科普,不錯過第一手消息~