Google 在一年一度的 Google Cloud NEXT 大會上正式推出新一代機器學習產品:Cloud AutoML,一次涵蓋了圖片辨識(Vision)、翻譯(Translate)、自然語言處理(Natural Language)三大範疇,服務主打能讓企業快速擁有客製化機器學習模型的產品,這究竟解決了機器學習領域中的什麼問題?對於台灣產業界來說又有何種影響性呢?
本篇文章將帶領讀者瞭解機器學習在實際引入企業時容易面臨到的一些困境,與 Google 的 Cloud AutoML 服務相應提出的解方,同時展望未來可能的產業潛在機會。
高階資料科學家供不應求、且組建團隊要價高昂
從 Google AlphaGo 到 Chatbot 聊天機器人、智慧理專、精準醫療、機器翻譯… 近年來時而聽到人工智慧、機器學習的相關消息,一夕之間這項技術攻占了各大媒體版面。不但 Google、Facebook、微軟、百度、IBM 等巨頭紛紛進軍該領域,NVIDIA 執行長黃仁勳亦宣稱將由顯示卡轉型成人工智慧運算公司,強調人工智慧浪潮的來臨。
然而適用於各行業革新的人工智慧技術,卻在目前的商業應用上遇到了幾個難題。
第一個困境在於,經驗豐富的專業資料科學家相對於龐大的企業徵才來說,供不應求的情況相當嚴重。
由於資料科學本身有著許多複雜的分支,涵蓋自然語言處理、電腦視覺等,資料科學家必須擁有強悍的程式能力如 R、Python,加上微積分、線性代數的數學底子,最後還要配合特定領域知識(Domain Knowledge)。
許多資料科學家也會深耕至資工/統計/數學的碩博士學位以應付工作需求。英國工作搜尋平台 Joblift 在 2018 年初調查過去 12 個月 8,672 個資料科學家的職缺,其中的 849 個職缺要求有博士學位,1,342 個職缺要求至少有碩士學位。相對高的進入門檻也導致了高階人才的稀缺性,
而根據 2016 年全台企業 IT 趨勢大調查,超過七成的企業仍面臨大數據與資料分析的應用困境。即便台灣的開放資料量為世界第一,全台的資料科學家卻僅有 1,092 人,在未來更將面臨需求人數大增 477%。
而第二點困境則在於──就算找的到人,對於中小企業而言,很少團隊有能力與預算能如同大企業一樣,聘請數十位年薪高達千萬的博士學位機器學習人才,來組建一支昂貴的資料科學團隊。
在人工智慧領域中,目前領先的四大巨頭分別 Google、Microsoft、Facebook 與百度 (Baidu),每個月都可以看到這四家公司公布新的技術發展並推出新的產品服務。每分每秒,AI巨頭們都在使用深度學習改變你我的生活。
研究機構 Gartner 指出,未來兩年內,全球超過半數大型組織企業,皆需靠資料分析服務決勝;然而當各家科技公司更是摩拳霍霍、無不想搶進最新發展時,難道機器學習與深度學習的應用與廣大的藍海市場,將會就這樣通通由大公司蠶食殆盡嗎?
隨著今年 Google 在舊金山舉辦的 Next 大會上正式推出新機器學習產品:AutoML 後,這個故事將開始變得不一樣了。
傳統訓練模型上不但耗費人工成本、也十分仰賴資料科學家本身經驗
資料品質一直都是機器學習訓練上最重要也最難掌握的一個階段。最大的障礙即在於「資料」,這包括需要大量品質良好的標籤資料。
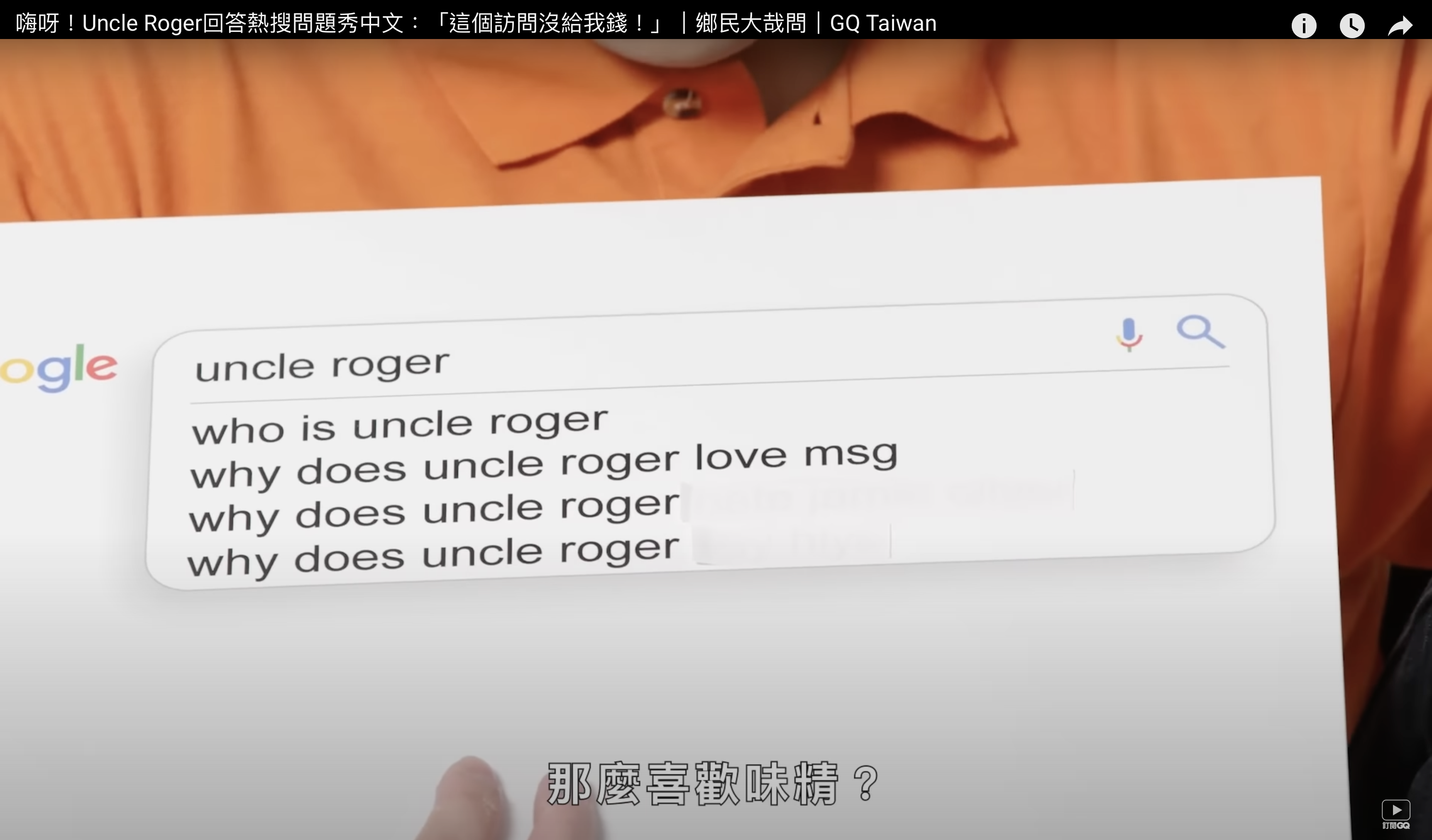
先來看看為什麼需要「標籤資料」。由於機器學習方法可分成監督式學習(Supervised Learning)與非監督式學習(Unsupervised Learning)。
在訓練的過程中告訴機器答案、也就是「有標籤」的資料,比如給機器各看了 1000 張各自標籤為蘋果或橘子的照片後、詢問機器新的一張照片中是蘋果還是橘子。
而非監督式學習的訓練資料則沒有標準答案、不需要事先以人力輸入標籤,故機器在學習時並不知道其分類結果是否正確。訓練時僅須對機器提供輸入範例,它會自動從這些範例中找出潛在的規則。
非監督式學習本身沒有標籤 (Label) 的特點,使其難以得到如監督式一樣近乎完美的結果。就像兩個學生一起準備考試,一個人做的練習題都有答案 (有標籤)、另一個人的練習題則都沒有答案,想當然爾正式考試時,第一個學生容易考的比第二個人好。
因此第一個問題在於:實際應用中,要將大量的資料一一進行標籤是極為耗費人工時間精力的一件事情。
第二個問題是模型調參與特徵工程上,需要具備豐富專業經驗的資料科學家作為支持。
除了標籤數千萬筆的資料需耗費大量人工,機器學習模型的選擇與評估上也是一個難題。資料科學家得根據所要解決的問題、擁有的資料類型和過擬合(Overfit)等情況進行衡量評估,配合自己的過往經驗來選擇性能合適的機器學習模型,並進行特徵工程(Feature Engineering)、把原始 Raw Data 資料轉換成特徵。
最後一個問題,是資料量不足導致無以訓練出一個夠好的模型,欲依靠遷移學習(Transfer Learning)時,同樣亦須仰賴資料科學家本身的經驗。
比如今天你今天必須使用一個新的資料集要做一下圖片辨識分類,問題是資料集中的資料也不多,你發現從零訓練開始訓練類神經網路模型的效果很差、也有可能會過擬合。
這時候就可以選擇使用遷移學習(Transfer Learning),使用別人已經訓練好的的模型。從頭開始訓練一個模型相當耗費時間,因此若能透過修改預訓練的模型、選擇性地載入類神經網路模型的權重,再用新的資料集重新訓練模型,相較於從頭開始訓練,能在更短時間內即達到相同的效果。也就是將已經訓練過的模型應用到新的資料集(Data Set)上。
![]()
由於語音識別與圖像識別等不同領域做遷移學習的方式也會不同,包括:把過去做得好的模型當成預訓練模型(Pretrained model)加入新的類神經網路模型;或是把其他領域的資料轉移(Transfer)到新的類神經網路模型、同時用兩個不同領域的資料來訓練。這樣的工作過程明顯需要資料科學家在訓練類神經網路上的豐富經驗,若經驗不足則可能難以找到夠好的訓練結果。
可以說深度學習模型導入實際應用中的門檻,一直以來都比我們的想像中更高。因此 Google AutoML 的出現,正是要解決上述三大問題,且方法十分地平易近人使用。
AutoML 讓 AI 來訓練 AI,不懂機器學習也能在企業中導入 AI
傳統建立機器學習模型時,得由資料科學家以程式碼撰寫機器學習的訓練模型(Model)、再佈署到 Google Tensorflow 框架上。然而 AutoML 利用簡單易用的使用者介面,即使是不具備機器學習專業知識的開發人員,藉由簡單的資料上傳與拖曳的動作,不需撰寫任何一行程式碼,只要使用者提供資料,隨後 AutoML 就會自動生成一個客製化的機器學習模型。
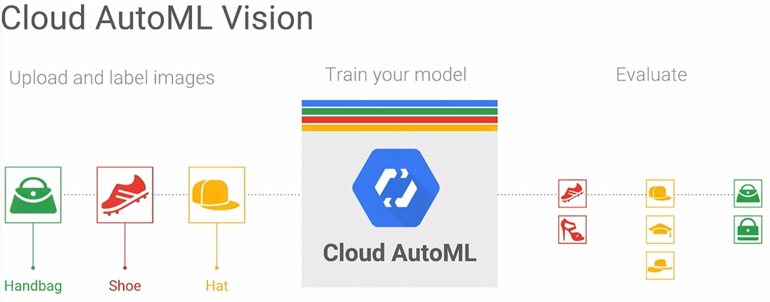
比如作為一個氣象預報員,只要將捲積雲、捲層雲、高層雲… 各式各樣的雲朵等標籤過後的圖片資料直接上傳到 AutoML 中,接下來就是由 Google 提供他們已經訓練好的模型,用遷移學習的方式直接幫你應用到最適合的模型上,直接就能成功進行圖像辨識。
AutoML 這項服務將使任何人都能藉此建立機器學習模型。進一步來說,AutoML 能自動挑選適合的模型,搭配超參數調整技術(Hyperparameter tuning technologies)自動調整參數,讓企業只要將原始資料輸入後,能夠建立出符合自家需求的預測模型。你只要提供資料,就算不懂機器學習技術也能自製企業級AI應用。
但你可能正在想:如果我的團隊中沒有足夠的人力來對數萬張照片一一進行標籤,該怎麼辦?
完全不用擔心,Google 提供了一個 Human Labelers 團隊,能根據指示進行圖片的分類標籤;使用者也可以利用 Google Human Labeling Service 來標註或清除標籤。
簡單來說,AutoML 主要提供了四大難以令人抗拒的優勢:
1. 資料量不夠?使用者只需要提供少量的標籤資料,Google 即幫你應用到 AutoML 上由 ImageNet 圖庫訓練出來的模型。
2. 團隊中缺乏足夠人力來為資料進行標籤?由 Google 出人幫你標籤資料,從頭到尾不耗費團隊人力。
3. 團隊中缺乏足夠豐富經驗的資料科學家來進行模型選擇或訓練?AutoML 使用已經有的標籤資料集,直接幫你應用到最合適的模型上。
4. 完全不用會寫程式,從上傳資料、標籤資料和訓練模型,都是透過介面拖曳即可完成。
想像這是多驚人的一件事情。數小時的時間內,AutoML 即能完成工程師得用個數週、甚至是數月才能完成的工作。
更令人驚訝的是,AutoML 創建的模型相較於設計 AutoML 本身的 Google 研究人員所設計的模型,前者的精確度更高──在一張圖片中標記多個物體名稱的測試中,AutoML 的精準度為 42%;然而由人類所撰寫的模型僅 39%。未來的趨勢將不再是由人類來訓練 AI,而是讓 AI 來訓練 AI。
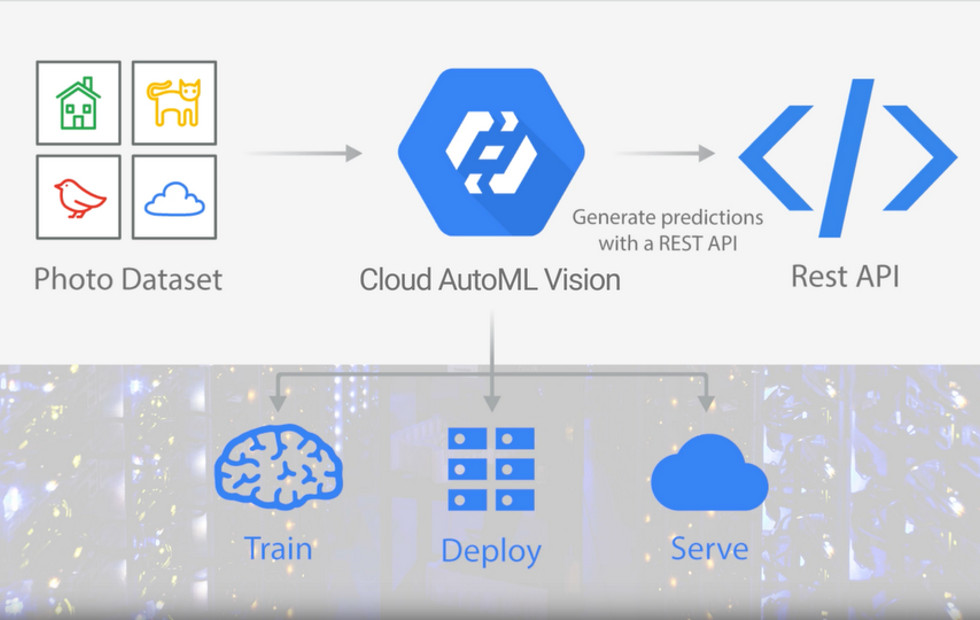
目前 AutoML 在 Vision(電腦視覺)、Translate(翻譯)、與 NLP (自然語言處理)均已在 Beta 測試版的階段,人人皆可以試用。該服務目前僅搭載支援圖像辨識的 Cloud AutoML Vision 服務。 Google 表示未來 AutoML 還會支援包括語音、推薦系統等所有常見領域的機器學習模型。
只要你擁有資料,即能創造千萬種創新商業模式
由於現在人工智慧技術成本與高技術經驗門檻的特性,使得中小型企業很難真正在企業中引入人工智慧到自身的應用服務中。有了 AutoML 之後,資料應用方式將會有了更多元的拓展方向,甚至能創造嶄新的商業模式。
舉例而言,一家製造機械零件的工廠老闆為了在廠房中導入工業 4.0 ,裝置了許多的感測器在機台上蒐集大量即時的資料,以偵測可能發生異常狀況的機台、及早在問題發生前即撤換零件以避免影響產能。
若製造類似機械零件的企業在全球有數千到數萬家之多,只要拿這些資料上傳到 AutoML、標籤不同的異常狀況判讀條件,最後產生一個相對應的 API 服務提供給其他有同樣產線監控需求的廠商,工廠本身即從數據中挖掘出了新的應用可能。
或一家醫院可能擁有數萬個患者資料,若是任意將資料外流給相應數據分析企業,則可能面臨病患隱私權侵犯的問題。隱私權與資料科學的應用上的權衡互相違背。然而醫院本身的資料若能經由病患同意後、上傳至 AutoML 中訓練出一組模型,並用於建立醫院本身開發的應用程式上,比如藉由輸入海量的 X 光圖片、並標籤好相對應的疾病,藉由 AutoML 最後訓練出來的模型來判讀未來新輸入的 X 光圖像,降低醫生人力成本的智慧醫療輔助將再也不是夢。即便將模型的 API 另外開放給其他有導入智慧醫療需求的機構診所,由於從模型中反推資料的難度,也較不涉及將原資料隱私外洩的問題。
更別提在生物醫學領域,新型的基因儀三天內即可測序 1.8 TB 的量,使的以往傳統定序方法需花 10 年的工作,現在 1 天即可完成。或在金融領域,以銀行卡、股票、外匯等金融業務為例,該類業務的交易峰值每秒可達萬筆之上。
根據EMC數位世界研究報告預估,從 2013 年至 2020 年間將成長 10 倍的資料量,資料總量將從 4.4 ZB 增加至 44 ZB。當全球各行各業的資料量成長急速攀升時,不用耗費高額預算、也不用外流資料的情況下,即能利用資料本身如金礦般強大的價值創造分析或預測服務,搭載於本身的應用程式上,開創嶄新的營收模式。
想實際體驗看看 Cloud AutoML 厲害的地方嗎?結合 AI 大眾化的趨勢,Google Cloud 首席合作夥伴:GCP專門家架設了「Cloud AutoML 獨家體驗專區」,讓所有人都能即刻感受 Cloud AutoML 的威力。
![]()
若想客製化擁有自己的 Cloud AutoML 模型,GCP專門家提供以下教學文章與應用案例:
1. [手把手教學] 快速啟用 Cloud AutoML Vision:Google 最新機器學習產品!
2. 如何應用 Cloud AutoML Vision 辨識屈中恆、宋少卿、鈕承澤!
想立即擁有自己的客製化機器學習模型嗎?想訓練模型卻不知從何下手嗎?立刻與 GCP專門家聯繫吧!瀏覽更多 Cloud AutoML 相關文章與 Google Cloud 產品應用,詳見 GCP專門家技術部落格,GCP 專門家的最新知識均在此與您分享。