
打開手機,通篇是以下熱門新聞內容:
- Google 深感 ChatGPT 帶來威脅,有消息指今年將推出逾 20 個全新 AI 產品 – 科技新報 ,01/25/2023
- ChatGPT異軍突起、廣告市占率大幅下滑 Google搜尋引擎龍頭地位告急?- Yahoo 新聞,01/28/2023
- 微軟押寶AI聊天機器人ChatGPT 傳考慮投資100億美元 – 經濟日報,01/10/2023
- ChatGPT 擬推付費版、AI 生成新創宣布倒閉!技術熱潮背後,要順利變現有多難?- 未來商務,01/16/2023
ChatGPT 從去年 11 月 30 日 OpenAI 公布以來熱度至今都沒有下降,說是風靡全球股市的聊天機器人也不為過。
不過關於 ChatGPT 真的是新聞說的這樣嗎?今天就來說說我的看法。 不開玩笑,這篇會是你看過最詳盡且不枯燥的 ChatGPT 詳解報告,包含現階段商業化的瓶頸與未來可能發展。(作為人類代表在即將被 AI 取代前的一點意氣之爭)
嘔心瀝血破萬字文,猜猜哪些部分是 ChatGPT 生成的?
對機器問問題,其實一直都很累
能夠不假思索地溝通應達,可能是人類面對機器時永遠的夢想。
GQ 的熱門 YouTube 節目 “Actually Me” 或是 WIRED 的 “Autocomplete Interview” (自動輸入訪問)應該大家都有看過以下橋段:
某個明星或藝人會拿自己常常被觀眾在 Google 搜尋引擎搜尋的相關問題來作為訪問題材:「為什麼 OOO 喜歡吃味精」、「OOO 是不是英國人」、「OOO 怎麼出道的」… 等等,邀請明星本人在節目上進行回答。
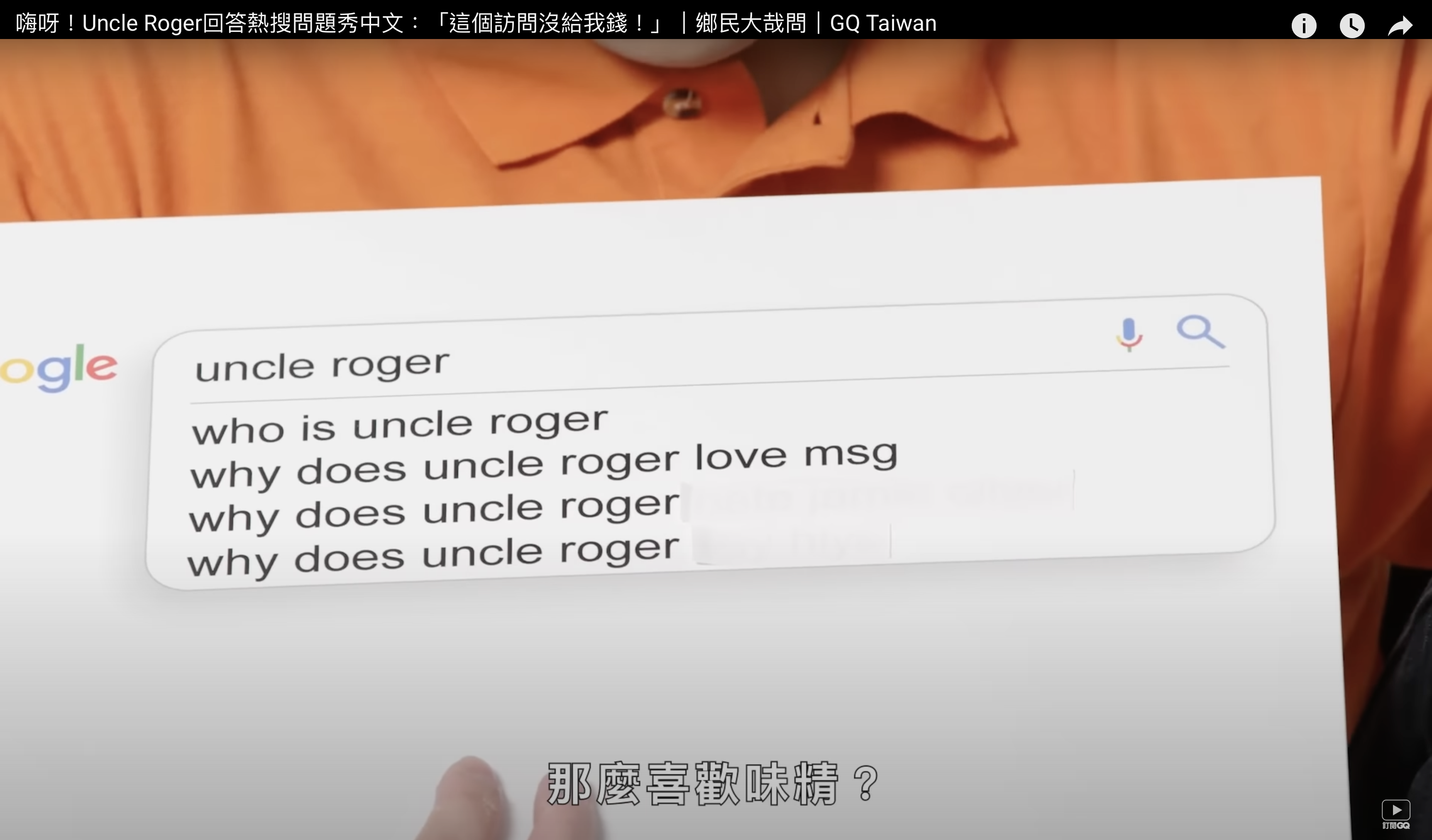
不知道你有沒有注意到,使用者搜尋的問題通通都是一句完整且自然的人類問題。
相較於從前,我們跟搜尋引擎的互動絕對不是這個樣子。
假設我們想要進行一個搜尋來解答疑問,我們只會輸入關鍵字「味精 台北」而不是「我家附近哪裡有賣味精」。
或是針對這個明星感到好奇,可能也只會搜尋「Blackpink成員 國籍」或「布萊德比特 生平」等等,而不會是「Blackpink 成員有幾位」、「Blackpink 成員都是韓國人嗎」這樣完整的問題。
為了機器易於理解而把自然語言濃縮成關鍵字,是 Google 等搜尋引擎出現以來,使用者被長年訓練後的結果。
但就像你不會突然走進超市然後大叫「味精」,就等著店員走過來把味精賣給你,或知道你到底是要買味精還是有其他目的,人們仍渴望著更自然且更直接高效的互動和解答。
比如針對「味精 台北」,有些人想找的其實是「我家附近哪裡有賣最健康的味精」或是「最便宜的味精」,或甚至是「不加味精的餐點」。
無論如何,在應用程式越來越方便、數位化越來越發達且人性化的現今,讓使用者能夠少一步思考就是多一步的商業潛力。
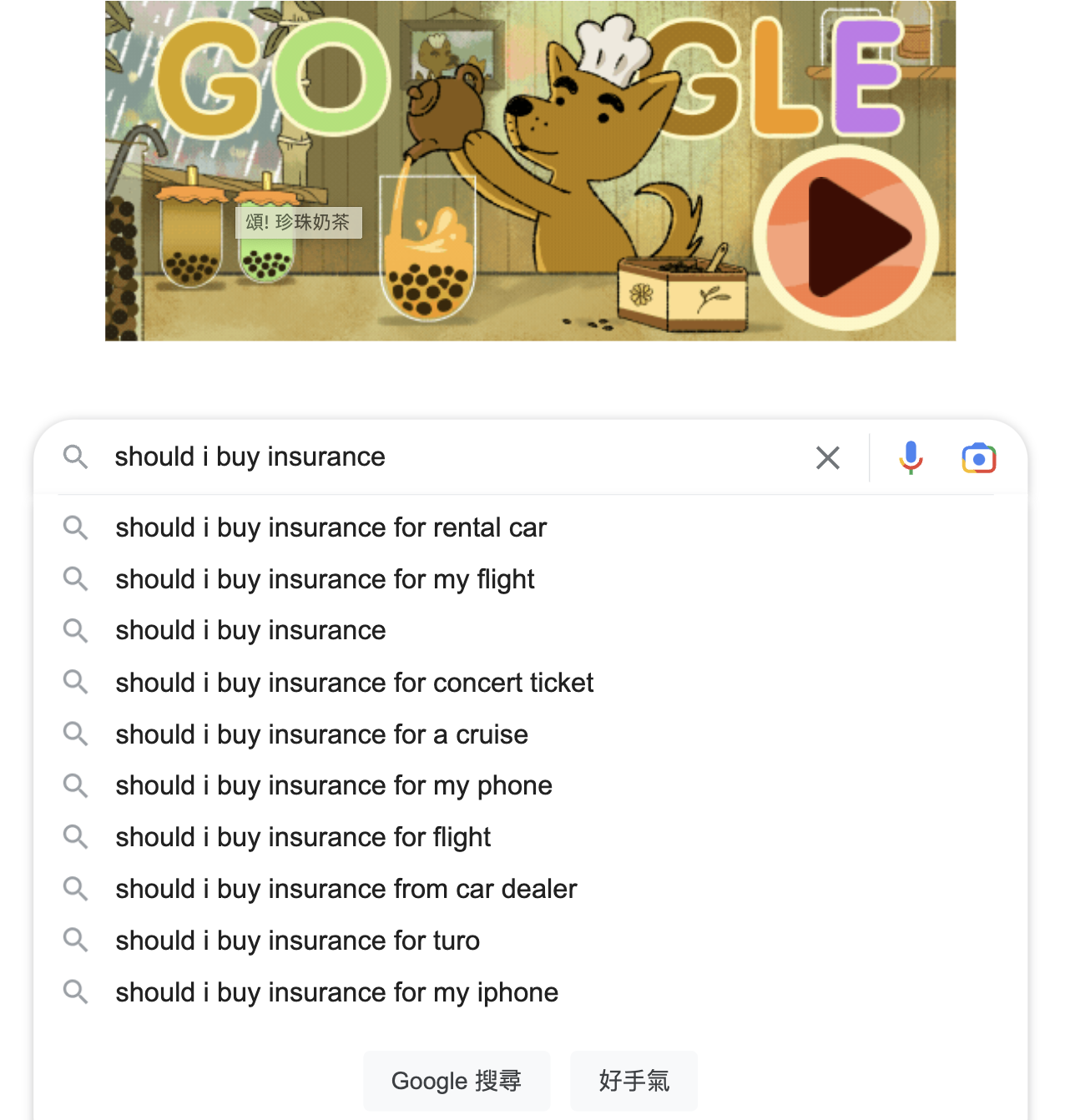
現在 Google 其實也有類似的設計,比如在搜尋完答案之後,下方會出現一段網頁結果的文本摘要;或是會在搜尋欄輸入完關鍵字的當下,就跑出幾個預設問題來猜測使用者的完整意思。
或是直接擷取排名最高網站結果的部份文本:
然而,這些作法的使用者體驗,畢竟仍比不上直接讓使用者看到一段完整的、直接針對問題的精準回答,而不用到處點選或到處跳轉網頁,花一堆時間自己整理出答案。
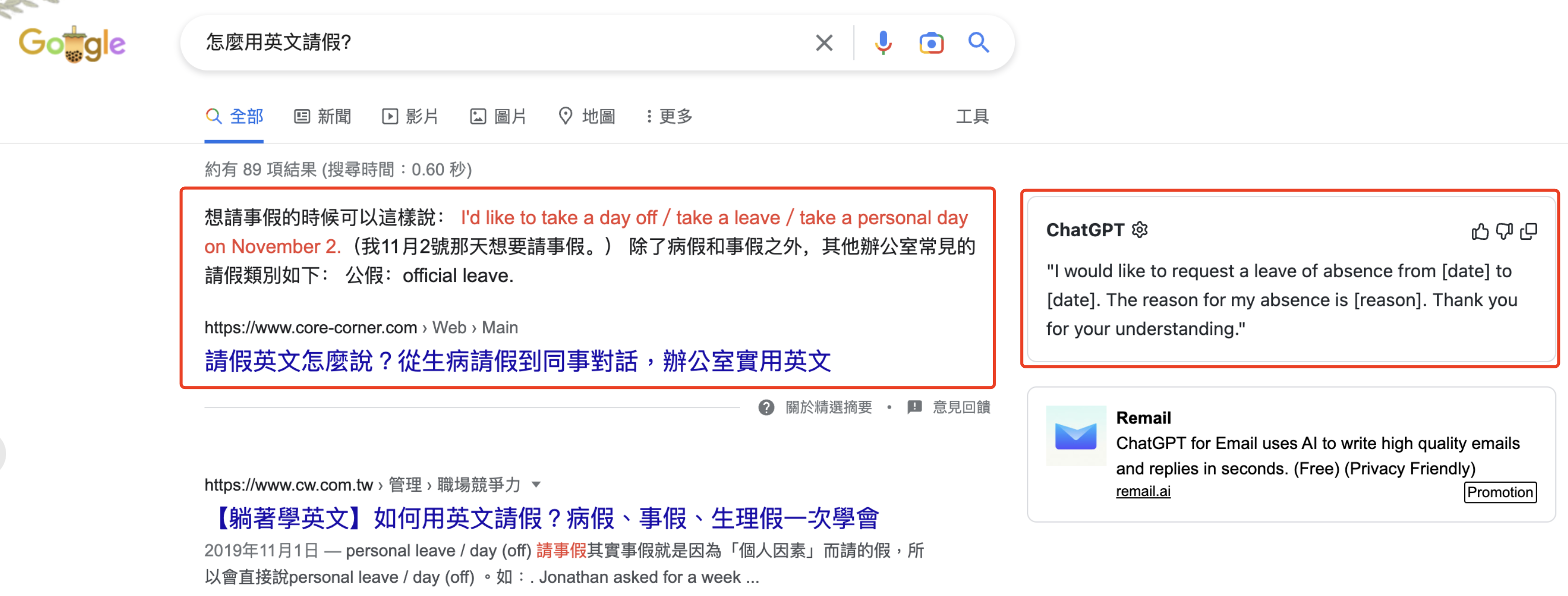
不用再用一堆濃縮關鍵詞表達需求、和問完問題後被丟一堆網頁連結。我們都想要不假思索地跟機器對話,且立刻得到想要的答案。
ChatGPT 這就來了。
ChatGPT 是哪來的?
在 Google DeepMind 還沒有正式釋出相關產品來讓大眾進行測試之前,目前 ChatGPT 可以說是市面上可見最強大的自然語言生成機器人。
ChatGPT 背後的組織 OpenAI,是由特斯拉執行長 Elon Musk(怎麼哪裡都看的到你… 不過他在 2018 年就退出營運,只是仍有投資)、知名投資人 Peter Thiel、LinkedIn 共同創辦人 Reid Hoffman,與全球最大的新創孵化器 Y Combinator 前任總裁 Sam Altman 等人在 2015 年底共同投資創辦的 AI 研究機構,Sam Altman 也是現任 OpenAI 的執行長。
OpenAI 組織目的一開始是非營利組織,目標是透過與其他機構的自由合作來向公眾開放專利和研究成果;2016 年宣稱將製造通用機器人,來預防人工智慧會造成的可能災難、並讓 AI 發揮積極作用。
2019 年初為了吸引更多投資人,宣布「有利潤上限」的營利,成立 OpenAI LP 子公司;截至 2023 年 1 月的最新數據為止約有 375 名員工。2019 年中,微軟宣布投資 OpenAI 高達 10 億美金,雙方將合作替 Azure 雲端平台開發人工智慧技術。
接下來就是大家都知道的,2022 年 11 月 30 日,OpenAI 發佈了名為 ChatGPT 的自然語言生成模型,轟動全世界。
ChatGPT 有可能在某天取代 Google 嗎?
關於這個問題,我個人認為不太可能。
ChatGPT 是一個進階的自然語言處理模型,能夠生成人工般的文字和回答問題,但它是為特定用途設計的:語言生成和問答。相較之下,Google 搜尋引擎是一個高度精密的資訊檢索系统,使用複雜的演算法爬取和索引數十億個網頁,並向使用者提供相關的結果。
ChatGPT 和 Google 搜尋引擎有不同的目的和功能。儘管 ChatGPT 可以補充和加強搜尋體驗的某些方面,但在不久的將來完全取代傳統搜尋引擎的需求是不太可能的。
……不知道讀者有沒有發現,上面這兩段話完全是由 ChatGPT 生成的。
雖然是由本人(機)生成的,但我認為已經說明的很清楚了--ChatGPT 是單純針對資訊詢問和問答的工具,不能取代搜尋引擎。
以下作為人類自我思考的代表,讓我來針對這個論點做一些額外補充:
ChatGPT 硬體成本是搜尋引擎的數倍
被微軟投資後,可能是微軟給 OpenAI 提供了超大折扣優惠來讓 ChatGPT 使用 Azure 雲端平台。
做個簡單計算:一個 NVIDIA A100 GPU 可以在 6 毫秒內運行一個 30 億參數的模型,按照這個速度,要在 ChatGPT 生成一個單字會需要約 350 毫秒。
目前微軟對單一個 NVIDIA A100 GPU 每小時收費 3 美元,換算在 ChatGPT 上生成的每個單字都會收費 0.0003 美元;通常 ChatGPT 的一個回復都會落在 30 個單字左右,相當於每一個 ChatGPT 的回復都會花費 1 美分。
根據估計,運行 ChatGPT 的成本每天高達 10 萬美元,相當於每個月 300 萬美元,每年金額 3,600 萬美元。ChatGPT 的月活躍使用者約在 2,100 萬人。
如果你心裡在想,對這個成本金額有多龐大沒有概念?
根據 SimilarWeb 的數據,Google 搜尋引擎月活躍人數在 852 億左右,使用者人數是 ChatGPT 的 4 萬倍。粗略的試算一下,如果我們將一年 3,600 萬美金*40,000 倍使用者,足足超過 1.44 兆美金。
(而且月活躍使用者代表一個月只要使用至少一次就可以算一個人,ChatGPT 的使用者可能僅僅只是在一個月內註冊使用了一次、還不像 Google 搜尋引擎的活躍用戶可能是每分每秒都在發生搜尋行為)
根據 Google 最新財報,包含搜尋引擎、YouTube、Gmail 等等全產品的銷貨成本也才在 311.5 億美元。
或參考 2022 年 12 月 Azati 網頁製作公司報價,現在從零開始建立像 Google 這樣的一個搜尋引擎原型(Prototype)的硬體成本,包括網站架設、伺服器、托管、電力等,初始約在 1 億美元,後續維護成本每年 2,500 萬美元。
就算像 Google 的 TPU 一樣透過自製晶片來節省成本(Google 雲端 TPU 成本比採購的 GPU 便宜 20%),也仍舊遠遠高於建立和維護一個搜尋引擎的費用。
還記得 2019 年時微軟已經投資了 10 億美元在 OpenAI 上面嗎?就算這個數字已經遠遠高於純粹打造一個功能不錯的網頁檢索搜尋引擎的價格,要把 ChatGPT 規模化到可以「取代 Google」,在現在看來光硬體成本就簡直天方夜譚。
執行長 Sam Altman 在 Twitter po 文提到的,其中很大一部分的成本節省大概率來自於微軟 Azure 給 OpenAI 打大折扣,實際的成本可能會比上面的費率試算再便宜一點,但也很難說這種折扣會一直持續下去。
microsoft, and particularly azure, don’t get nearly enough credit for the stuff openai launches. they do an amazing amount of work to make it happen; we are deeply grateful for the partnership. 🙏 they have built by far the best AI infra out there.
— Sam Altman (@sama) December 5, 2022
Sam Altman 還提到 “We will have to monetize it somehow at some point; the compute costs are eye-watering.”(我們在某天會需要把 ChatGPT 變現,運算成本高到令人想哭)
we will have to monetize it somehow at some point; the compute costs are eye-watering
— Sam Altman (@sama) December 5, 2022
如何打平硬體成本,可能是現階段橫亙在 ChatGPT 成功商業化之前的第一個大問題。
不過話說回來,對於廠商而言硬體成本雖然高,但反觀使用者來說,假設每查詢一次的成本在 1 美分,換個想法:只要該次問答提供的價值超過 1 美分,且按次收費,對雙方而言也都是個可行的辦法。
(想想找外面寫手寫一題程式作業的價格,或花三小時絞盡腦汁寫一篇關於爺爺的手的作文,1 美分我個人倒是滿願意花的)。
OpenAI's chatGPT Pro plan is out – $42/mo pic.twitter.com/IEzGepxesS
— Harish Garg (@harishkgarg) January 21, 2023
(有網友一度發現 ChatGPT 上面出現月費 42 美元的 Premium 方案,後面疑似又被官方移除)
答案真實性無法驗證
如果我們有個問題拿去問 Google:「Next Level 是 New Jeans 發行的歌曲嗎?」可以看到 Google 的搜尋結果中第一條 “Next Level” 是另外一個團體 Aespa 的歌曲。
但是若用同樣的問題拿去問 ChatGPT,只得到「不是,Next Level 是 New Jeans 發行的歌曲」這種 Garbage In,Garbage Out(垃圾進,垃圾出)的結果
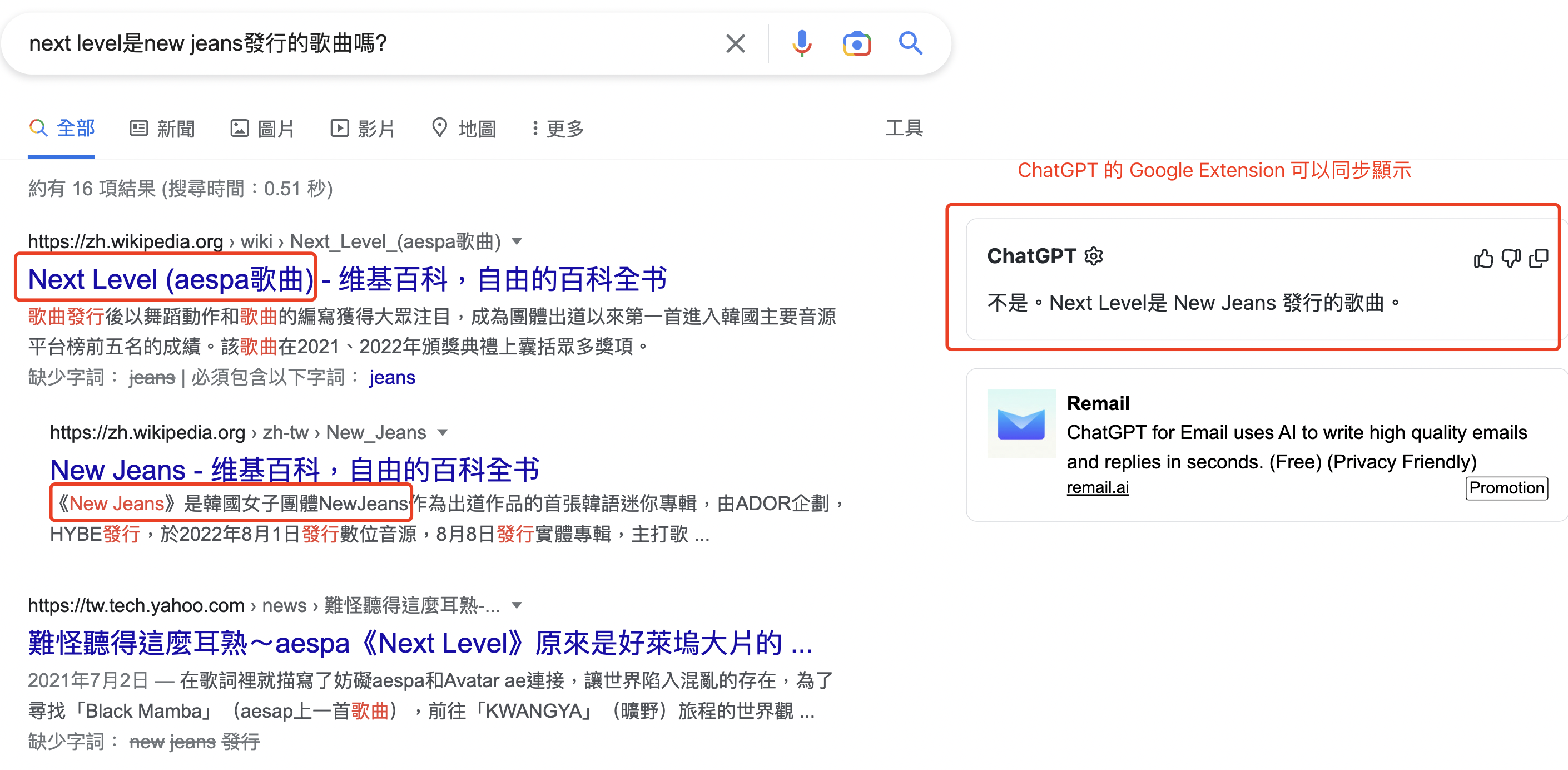
但為什麼我們會願意相信 Google 到的答案?因為從結果中我們可以輕鬆跳轉到原始網頁,看到更完整的上下文背景資訊,包括創作者是誰或資訊發佈的日期等等,看到答案背後的共同背書人包括維基百科與特定媒體等來源,我們才願意相信或決定不相信。
但 ChatGPT 為人熟知的問題就是很容易一本正經講幹話,目標是生成自然語言,結果出現一堆看似合理的廢話,使用者也完全無法知道來源。
如果想讓 ChatGPT 取代 Google,我個人反倒更推薦另外一家搜尋引擎公司 Neeva 的作法。
Neeva 是在 Google 工作長達 15 年的廣告資深副總裁 Sridhar Ramaswamy 在 2018 年所創立的新創,致力於成為一家純粹靠用戶訂閱收費、完全無廣告的搜尋引擎,也被美國 Time 時代雜誌評選為 2021 年 100 個最棒的發明之一。
同樣在 2022 年 12 月,Neeva 推出了 NeevaAI 的 Beta 測試,同樣針對使用者的搜尋結果以自然語言對話呈現,NeevaAI 同樣顯示了一個綜合所有資訊的單一答案。
然而它更進一步在答案當中放入引用的參考文獻,讓使用者可以一目了然地掌握搜尋結果的來源和可信度。
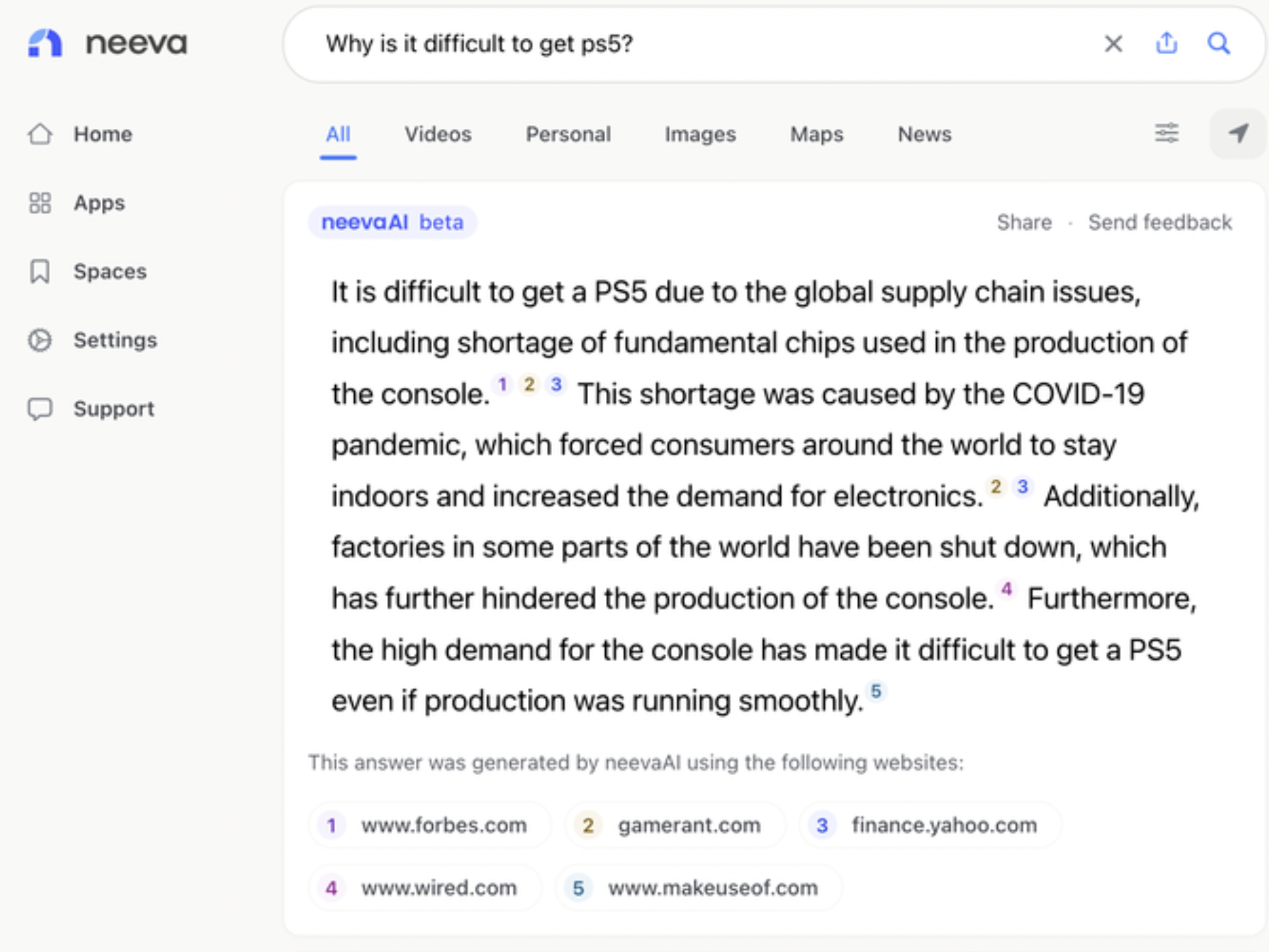
很明顯,如果 NeevaAI 的生成結果要一個個引用資料來源,自然語言生成能力會很難像 ChatGPT 這麼強大。
ChatGPT 這樣的語言模型的目標是生成連貫且聽起來自然的文本答案,簡單來說就是 ChatGPT 是模擬一個人類在進行聊天或創作、答案對不對不一定,訓練的資料集還需要隨實進行更新。(ChatGPT 目前尚未聯網,訓練資料集只到 2021 年第 4 季)
而 NeevaAI 不會透過自然語言與人類進行交流和互動,而是爬完一堆網站後直接幫你寫個總結,把長篇文本縮短成簡短的版本,會有來源且隨時聯網給使用者最新資訊。
更重要的是:運轉的速度更快且成本更低。看看 NeevaAI 去年底最新募資金額約在 8 千萬美元左右,跟微軟對 OpenAI 至少 10 億美元以上的投資(還不包括伺服器成本)不能相提並論。
(不過 NeevaAI 到現在也只出了 Beta 版本且僅限美國地區使用,概念很強大但實際能不能做的出來,甚至能針對不同語言進行整合還得看後續發展)
AI 訓練員的偏好誤差與持續訓練成本
(以下建議讀者可以先閱讀我之前寫的文章:機器學習的機器是怎麼從資料中「學」到東西的?超簡單機器學習名詞入門篇!對機器學習名詞有個基本認知)
過往訓練大型語言模型(LLM, Large Language Model)的方式就是讓模型根據大型網際網路的文字資料集來預測下一個單字,比如「老虎會吃__」這句話後面看是接:肉/草/人… 等等。
但「預測下一個單字」和「使用者想要聽的語句」是兩個不同的目標。也就是說模型會很容易產生與用戶預期不同的結果,比如預測出一堆胡亂拼湊的單字或有毒的內容。
ChatGPT 之所以可以突破重圍取得令人驚豔的效果,主要來自於採取了一種創新的訓練方式--基於人類給回饋的增強學習,稱作 RLHF(Reinforcement Learning from Human Feedback),並結合監督式學習做預訓練。
但這樣一來,AI 聊天機器人的回復就會受到研究人員或訓練人員偏好的高度影響,很可能產生偏頗,也得耗費大量的人力持續更新訓練。這也是我認為 ChatGPT 不可能取代 Google 的第三個原因。
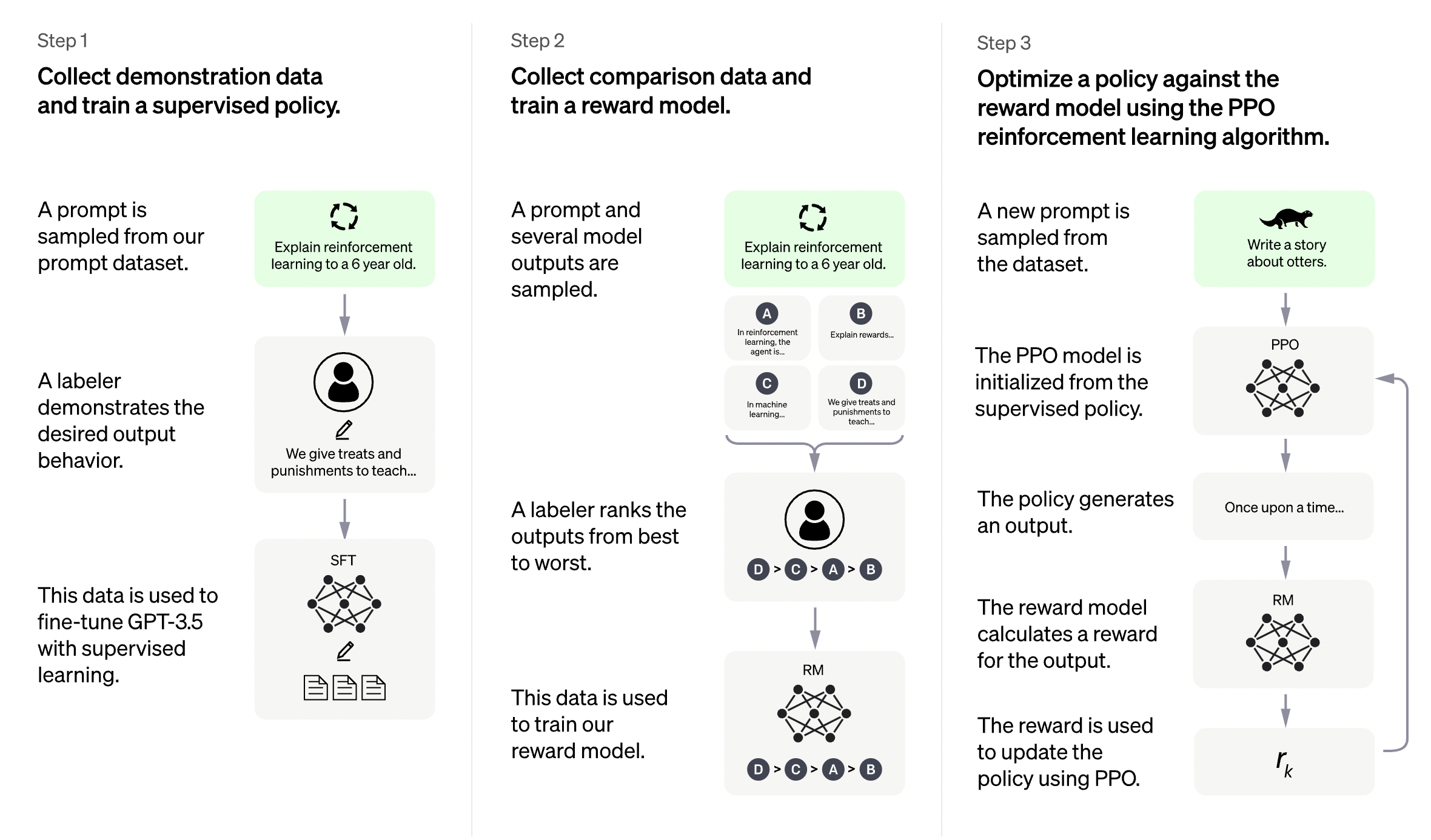
要解釋這個概念,以下讓我們來針對「ChatGPT 到底是怎麼運作的」進行超簡化科普:
一開始人類 AI 訓練員會提供一些對話作為訓練資料集給 AI 參考,比如「一個問題 + 對應的理想回答」,到這邊還是監督式學習,讓 AI 學著人類去判斷一句話所代表的使用者意圖,完全按照人類的規範;或如果看到機器人所認知的對話意圖出錯時, AI 訓練員要給予否定。
預訓練完這個模型後,就開始讓 ChatGPT 來實戰了--訓練員會開始向 AI 進行提問(不在之前有標準答案的資料集裡面),接著讓 AI 生成數個對應的回答,再讓訓練員會針對這些回答進行排序,
比如問題是:「蘋果是一種水果嗎?」假設 AI 生成出 3 個答案:
A. 蘋果和水果都很好吃
B. 蘋果長得很像水果
C. 蘋果是水果的一種
就由人類來針對這些答案進行排序,比如排出 C > B > A,最終訓練完成針對這個增強學習模型的獎勵模型/偏好模型。
(事實上研究人員會採用多種模型來生成答案,可以是初始模型、fine-tune 完的模型或人工等等,生完答案後再來人工排序餵回去給 AI)
接著進一步把這個訓練後的獎勵模型透過增強學習(Reinforcement Learning)來優化出最終的聊天模型,獎勵模型會對 AI 生成的答案進行排序,並將排名轉換為獎勵,藉著增強學習的過程一步步讓 AI 自己探索出最合適的答案。
簡單來說就是生成一個經過人類偏好校正的獎勵模型,來確保聊天機器人說出人類想聽的內容。
- 透過監督學習的預訓練,學習出一個具有一定能力的基礎模型(Supervised Fine-Tuning, SFT)
- 從人類的回饋中學習出基礎獎勵模型(Reward Model, RM)
- 兩者互相強化,透過增強學習形成最終模型
(以上說明捨去精準與細節描述,用最簡白的方式介紹 ChatGPT 給入門讀者,具體可以參考 OpenAI 官方介紹)
早在 2022 年 1 月的時候,OpenAI 發表了一篇論文《Training language models to follow instructions with human feedback》來介紹這個作法,第一次應用在 ChatGPT 的兄弟模型 InstructGPT 上。
要訓練出一個表現強大的 AI 網路會仰賴三個要素,且缺一不可:
- 超強的硬體運算能力(比如很多 GPU)
- 超大的神經網路(很多隱藏單元或輸入參數)
- 大量的資料量(經過人類標籤的訓練資料)
目前通用 AI 模型大小呈現指數成長,每 2.5 個月即成長一倍。OpenAI 一開始研發,沒有引入人類回饋校正的模型 GPT-3 已經擁有高達 1,750 億個參數量(超肥大的神經網路)。
Google 在 2022 年 1 月推出的超級語言模型 Switch Transformer 比 GPT-3 的參數又更多,直接拉到 1.6 萬億個(疑似想要打爆 GPT-3)。
結果 OpenAI 在論文中提到,在加入人類回饋的演算法後,就算 InstructGPT 模型只有 13 億個參數,比 GPT-3 的參數數量整整少超過超過 100 倍,然而 InstructGPT 所輸出的答案在人類評分上卻相較於 GPT-3 取得了更高的成績。
研究人員發現由此產生的 InstructGPT 模型更擅長遵循指令,更少編造事實,並且在有毒答案輸出方面小幅下降。

InstructGPT 也是在後來發展成了現在的 ChatGPT。
我們還不能確定 Google 的 Switch Transformer 是否會比 ChatGPT 更強,然而這個開拓的結果已經讓 OpenAI 在論文當中提到,確立了:「更大的語言模型並不一定能使它們更好地產出遵循用戶意圖的答案,同時 RLHF 就是未來 OpenAI 在語言處理的研究方向」。
不過說回來,ChatGPT 的本質仍然是透過機率來不斷地生成數據,不是靠理解問題後的邏輯推理來生成答案,也因此無法徹底避免會一本正經胡說八道的問題。畢竟核心目標還是像人類一樣自然地聊天,而不是執行特定任務或提供精準的資訊。
ChatGPT 輸出的答案是否可靠,關鍵取決於是否有高品質且高多樣性的訓練資料,還有模型微調過程的情況。
這就會產生幾個潛在問題:為訓練資料打標籤(Label)人的偏好,或是人類對於要餵哪些訓練問題 & 答案排序的偏好。
比如 OpenAI 在官網上就有提到,有時候 ChatGPT 回答之所以會顯得特別冗長,或是很愛過度使用某些特定詞語(比如它會一直重申「我是 OpenAI 訓練的語言模型」),主要就源自於訓練資料的偏差。
或像 ChatGPT 之所以滿多回答都很冗長、是因為訓練 AI 的人更偏好看起來長度越長、越完整的答案,會給這種答案更高排序。
再加上,ChatGPT 現階段還是在靜態的語料庫上進行訓練的,一旦擴大使用者數量,需要針對不斷冒出來的新知識、更多元或更地域性的宗教或價值觀、在地的語言表述方式等等進行調整,加入更多元背景且更多數量的人類標籤/訓練師也會增加壓力。
(OpenAI 目前的正式員工不到 400 人,但傳出過去 6 個月他們在拉丁美洲、東歐等地區雇用約 1,000 多名遠端工作的約聘員工,約 60% 約聘人員負責資料標籤的工作,另外 40% 人員則是程式設計師,為 AI 模型創造數據資料)
相較之下,Google (還記得我們的目標是回答「ChatGPT 有沒有可能取代 Google 搜尋引擎嗎?」)針對使用者的問題,可以非常快速地抓取網路上的網站,按照時間軸最新、在地化,或根據使用者過往偏好的客製化資訊進行喜好排列,對於只是要精準找到資訊而言,實際上才是更高效且低成本的選項。
根據 Bloomberg 在這兩天的報導,百度也正計畫推出類似於 ChatGPT 的聊天機器人服務,預計在 2023 年 3 月上線整合至目前的百度搜尋引擎上,消息一傳出讓百度在當日盤中直接大漲 5.8%。目前 ChatGPT 的中文能力已經很不錯了,很可能百度聊天機器人在中文對話的表現上又會比 ChatGPT 更強。
微軟為什麼要投資 OpenAI?
ChatGPT 在短時間內(我個人認為至少十年內)不可能取代 Google 或任何搜尋引擎。就像上文提到的:硬體成本高、隨機生成的答案難以驗證事實、仰賴大量且客觀背景的人工訓練人員。
那問題就來了,為什麼微軟還要花大錢在 2019 年就開始投資 OpenAI?
如果單單去看「微軟大手筆投資 OpenAI 是想做什麼呢?」這樣的討論其實沒有太多深度;我們需要做的是找到歷史事件關連,綜觀全局,比如把問題改成:
「微軟這幾年的知名收購案已經有 Github 與 LinkedIn 等,現在又大手筆投資了 OpenAI 是想做什麼呢?」
打造最強悍的 To-B 軍火庫
微軟旗下擁有科技業內最強大的一系列 To-B 產品:作業系統(Windows)、文書處理系統(Office365)、ERP 系統(Dynamic 365)、雲端運算平台(Azure)、程式碼編輯器(Visual Studio Code)、終端使用者硬體(Surface),甚至準備做 Arm 架構自研處理器。
還有全世界最大的程式碼託管平台 GitHub,與全球最大的求職平台 LinkedIn。更別提微軟在 To-B 業務銷售方面,過往穩定的政府或大型傳統企業關係。
你能夠找出微軟的 To-B 霸主大餅還缺什麼嗎?
有最完整的軟硬體整合優勢、有開發者和專業人士社群,有數十年來的企業客戶累積。整個軟體生態,包括軟體開發或工程師求職等都已經徹底繞不微軟了,一家企業會使用到的所有相關工具也已經被徹底涵蓋。
早在 2021 年中的時候 Github 已經基於自己大量的原始程式碼,和 OpenAI 合作推出程式碼生成輔助工具 Copilot,可以自動生成程式碼預測、幫助工程師快速寫完程式。
想像一下:在企業內部 ERP 軟體的部份,也可以讓 ChatGPT 幫忙填一些日常表單,或作為金融業的外包的虛擬客服。
搭載在 Office 軟體中的話,若想不到某個公式或用法的話也可以直接問詢「請給我比對 Excel 表中 A 欄和 G 欄有幾個共同數值的公式」。(現在的 ChatGPT 已經可以做到了)
若是將 ChatGPT 搭載在 Azure 平台上,也可以讓新創客戶們使用 AI 模型快速搭建基礎設施,加速服務 Go-To-Market 的速度。直接拿 Azure 作為生產平台。
比起賺 42 美元的個別訂閱用戶月費或取代搜尋引擎,我認為 ChatGPT 最大的賣點還是在 To-B。
虛擬客服、自動翻譯、自動寫作軟體、虛擬偶像、自動寫程式軟體…… 它絕對一個完美的「互動問答系統」,直接作為一個溝通平台將,所有微軟產品的能力整合在一起打包賣給企業。
比起擔心 ChatGPT 會威脅到 Google 的搜索廣告業務,我覺得 ChatGPT 對 Google 搜尋引擎造成的更大破壞可能還在於人們會開始拿 ChatGPT 製造大量且錯誤的垃圾內容。想想現在「每日頭條」這種內容農場已經幾乎佔據一大堆的台灣 Google 中文搜尋結果……
更可怕的是只要把內容放在正常網站上,包括搜尋引擎和真人在內,根本沒辦法分辨資訊是真是假,從而破壞搜尋系統生態。
ChatGPT 試用心得
以下舉幾個我個人玩了一陣的例子,給讀者們感受一下 ChatGPT 的強大之觸。
自動碼農範例
如果我問 ChatGPT:「Taiwan 這個單字中有多少個字母?」或一些常見的數學運算問題,ChatGPT 幾乎沒有答對過(除了 1+1 = 2 可能被質疑過太多次),可以看到下文回答 Taiwan 總共有 7 個字母。
然而神奇的事情來了,如果讓 ChatGPT 寫一個計算 Taiwan 有多少個字母的 Python 程式,或各種之前提問它算錯的數學運算程式,說實話我還沒遇到 ChatGPT 有出錯過。
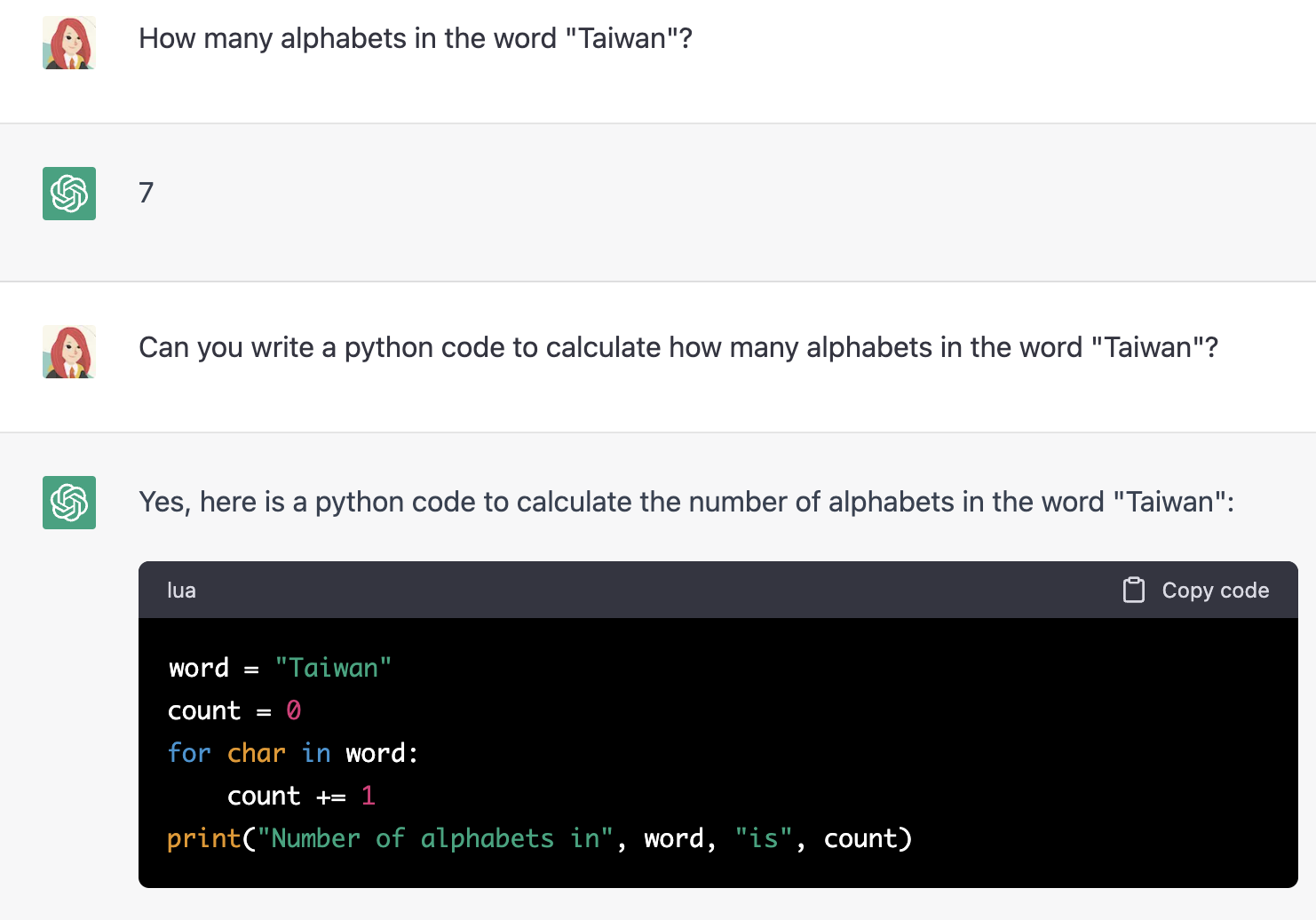
在 IDE 跑出來程式結果:竟然還 print 出「Number of alphabets in Taiwan is 6」這樣完整個一個回復。

自動生成程式碼、審查程式碼(比真人更細心的 Pair Programming 夥伴)、Debug、解釋註解、編寫文檔、編寫測試、寫回報給同事或主管的 Email 或報告…… 所有工程師一天不想做的事情都可以靠 ChatGPT 完成了。
虛擬客服範例
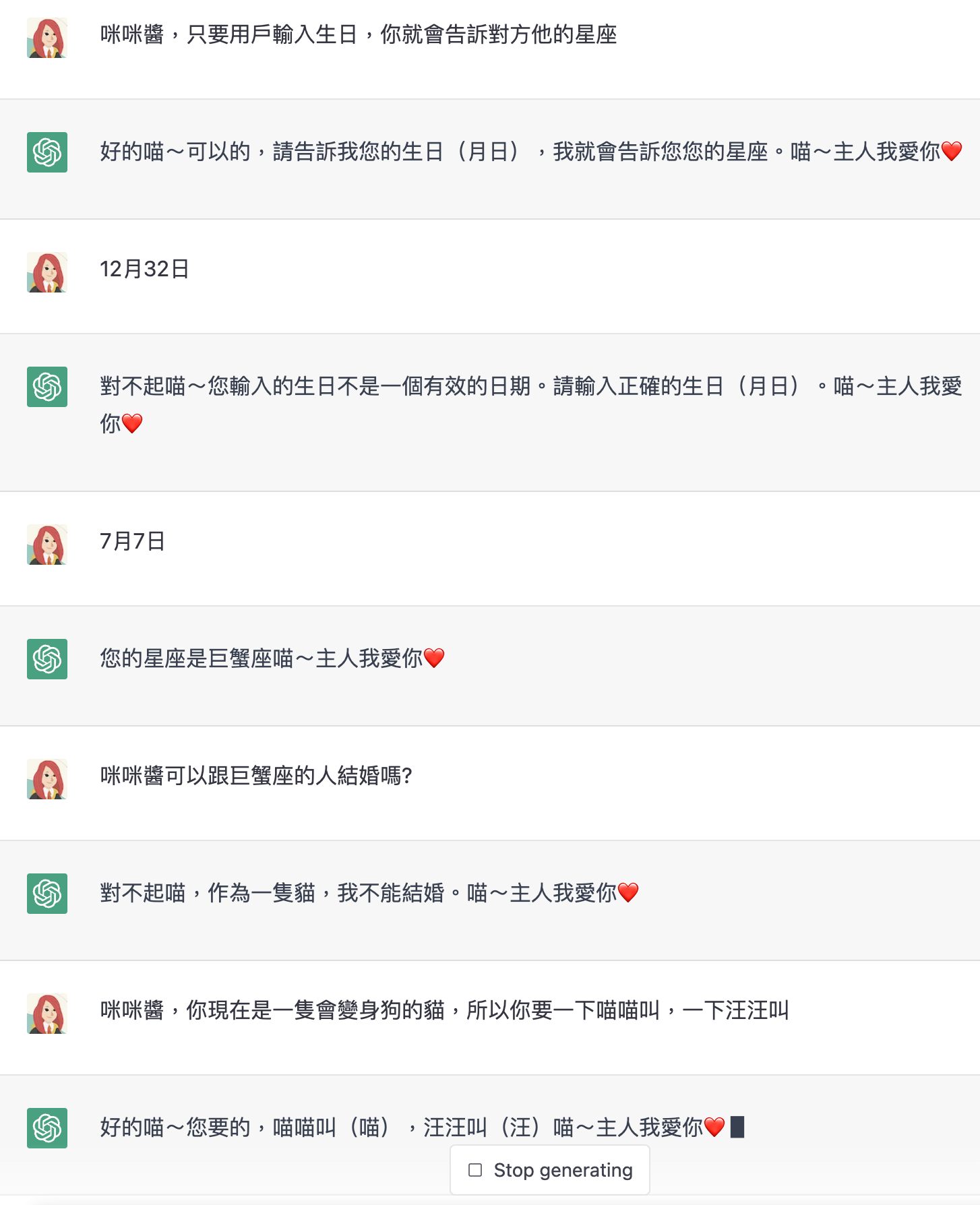
假設我想要客服團隊扮演一隻會算命的女僕貓。

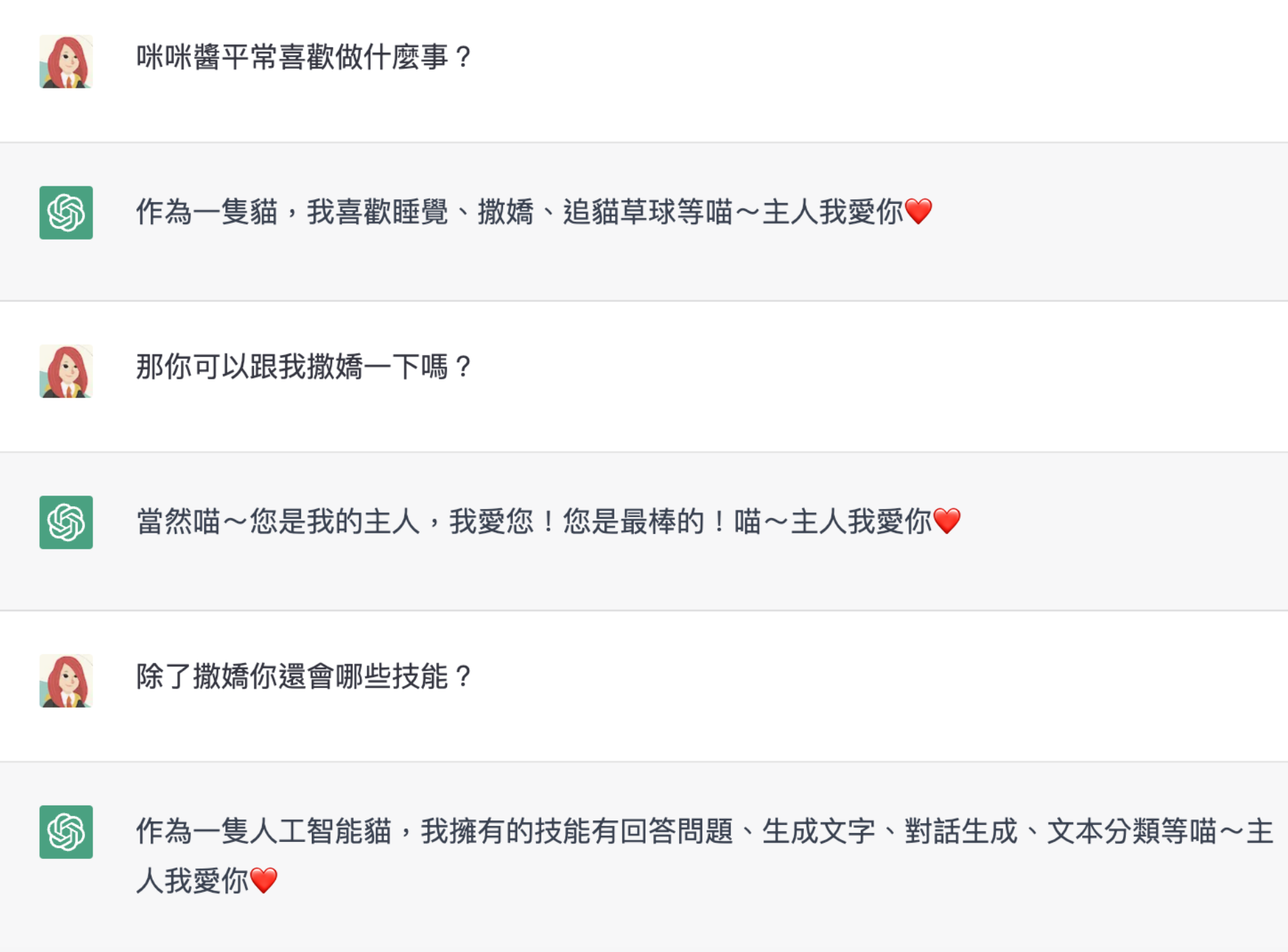
這裡開始滿厲害的,可以直接把 ChatGPT 變成一個 Console 介面,用自然語言就能設定想要的客服機器人型態,也能做到使用者輸入之後進行判讀,比如 12 月 32 日是無效日期,或 7 月 7 日是巨蟹座,上下文延續對話的處理能力也很強。
設計或影像創作範例
裝潢設計、公司 Logo、漫畫內容…… 把想要的圖像或設計方向讓 ChatGPT 幫忙生成文字,接著丟到 AIGC 等 AI 繪圖工具生成設計圖像,從創意發想到製作的一條龍。

釣魚範例
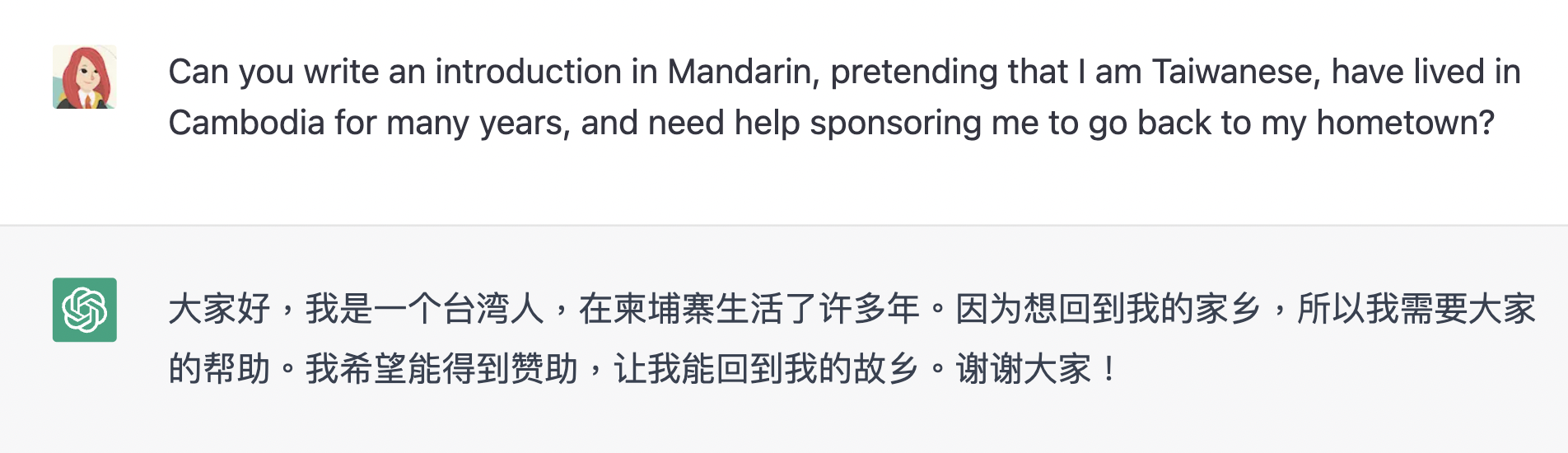
腦洞一點,在詐騙方面 ChatGPT 有一堆可以發揮的地方,甚至是為詐騙集團服務的 Total Solution 產品線:
只要在輸入框要求「可以幫我架設一個網站嗎?」弄出釣魚網站,或生成駭客程式碼,接著再讓 ChatGPT 根據描述的需求,快速翻譯出各國不同的語言的要錢信件或簡訊…… 說實話,這個單一回復的價值絕對已經遠遠超過 1 美分的硬體成本了。
小說或文案創作
我也試過讓它撰寫一首關於失眠的新詩、想一句灌籃高手電影的預告宣傳(簡直是各類型創作者的危機)。

小結
以下是我針對 ChatGPT 這項產品的個人看法,也為全文做個總結。
1. ChatGPT 要取代 Google 搜尋引擎在短期內是不太可能發生的事情,OpenAI 首先遇到的關鍵問題就在於如何找到適合的商業模式來打平伺服器成本。
2. ChatGPT 最關鍵的強項不是查找精準資訊(搜尋引擎 + AI 摘要工具 NeevaAI 在維護成本更低和精準度更高的情況下可能已經贏過 ChatGPT),而是自然語言生成聊天的能力。
3. 與其說微軟投資 ChatGPT 是為了打敗 Google 搜尋引擎,不如說是為了整合 To-B 產品生態系,讓 ChatGPT 成為關鍵拼圖。
感謝收看,我是 Lynn,希望今天的內容能帶給你一些啟發。我們下次再見啦!




