1950 年代電腦發明以來,科學家便希冀著利用電腦創造出人工智慧;然而當時的硬體效能低落、數據量不足,隨著通用問題解決機、日本第五代電腦等研究計畫的失敗,人工智慧陷入了第一次的寒冬。
人工智慧「現代鍊金術」的惡名,一直到 1980 年代開始才又復興。此時科學家不再使用傳統的邏輯推理方法,取而代之的是結合機率學、統計學等大量統計理論,讓電腦能透過資料自行學會一套技能,稱為「機器學習」。
機器學習方法有許多種不同的模型,此間爆發了兩次浪潮,第一波興盛的模型為「類神經網路」、又稱人工神經網路。類神經網路在剛出現時大為火紅、然而在不久後卻遇到了運算瓶頸,一下又沒落了下去,1980 年代中期,由其他機器學習模型,如支持向量機 (SVM) 模型作為主流。
一直到 2006 年,多倫多大學的 Geoffrey Hinton 教授成功解決了類神經網路所遇到的問題、讓類神經網路重新換上「深度學習」的名字捲土重來;如今深度學習技術對各大產業領域都將產生深遠的影響,堪稱第四次工業革命。
今天就讓我們來談談,機器學習模型的第一波浪潮「類神經網路」、其原理和瓶頸;與第二波浪潮「淺層機器學習」如:支持向量機 (SVM),之所以一時間取代類神經網路、作為機器學習的主流熱門技術的原因。
(備註:文中會有簡單的數學公式,但讀者不用害怕,只要大概理解基本原理即可。)
第一次浪潮:類神經網路 (Neural Network)
1950 年代的人工智慧走入了漫長的寒冬期,直到 1980 間,機器學習方迎來了第一個春天,這個春天叫做「類神經網路」,為電腦科學家由生物大腦的神經元運作方式所啟發、因而建立出來的數學模型。
1981 年,美國神經生物學家 David Hubel 和 Torsten Wiesel 對於動物視覺系統的處理信息方式有了進一步的發現,因而獲得了諾貝爾醫學獎。
他們把貓的頭骨開了一個小洞,向內插入微電擊、埋入視皮質細胞中,然後在小貓眼前放置一個會投射出光影的布幕,並不時改變光影的角度、亮度與大小。經過數次實驗與無數隻小貓的犧牲 (OAQ),Hubel 和 Wiesel 發現,不同的視覺神經元對於不同光影的反應不盡相同──在不同情況下的視覺神經元有著不同的活躍程度,甚至只對圖像的某些特定細節有反應。
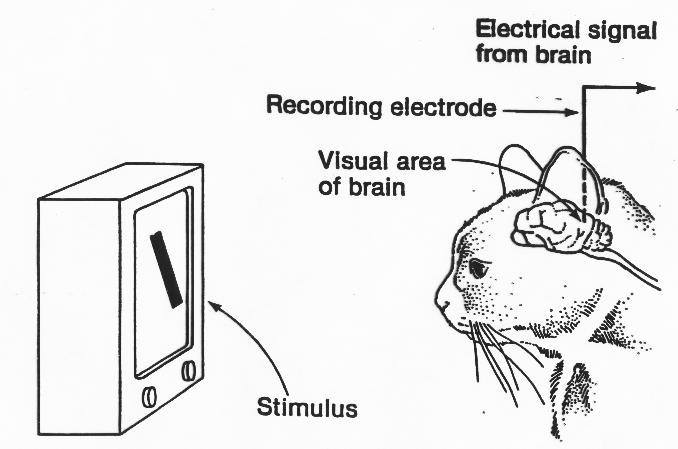
生物學上的神經元研究,啟發了 AI 領域關於「類神經網路」(或稱人工神經網路) 的概念。神經系統由神經元構成,彼此間透過突觸以電流傳遞訊號。是否傳遞訊號、取決於神經細胞接收到的訊號量,當訊號量超過了某個閾值 (Threshold) 時,細胞體就會產生電流、通過突觸傳到其他神經元。
為了模擬神經細胞行為,科學家設定每一個神經元都是一個「激發函數」,其實就是一個公式;當對神經元輸入一個輸入值 (input) 後,經過激發函數的運算、輸出輸出值 (output),這個輸出值會再傳入下一個神經元,成為該神經元的輸出值。如此這般,從第一層的「特徵向量」作為輸入值,一層層傳下去、直到最後一層輸出預測結果。
至於神經元裡面的激發函數公式是什麼呢?1957 年,Rosenblatt 提出了感知機(Perceptron)模型。
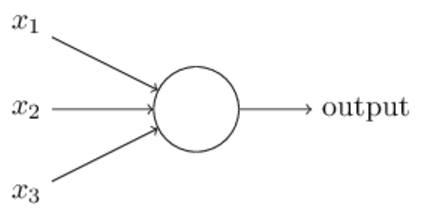
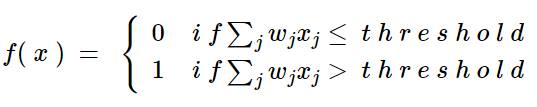 將特徵向量 X1, X2, X3 輸入進感知機後,感知機會分別給予一個對應的權重,分別為 W1, W2, W3。若特徵向量和權重的內積結果大於某個閾值 (Threshold) 時,輸出結果為 1 (代表電流會傳遞)、若小於閾值則輸出 0 (代表電流不傳遞)。
將特徵向量 X1, X2, X3 輸入進感知機後,感知機會分別給予一個對應的權重,分別為 W1, W2, W3。若特徵向量和權重的內積結果大於某個閾值 (Threshold) 時,輸出結果為 1 (代表電流會傳遞)、若小於閾值則輸出 0 (代表電流不傳遞)。
利用感知機模型,可以解決機器學習的基本二分法問題:將類別僅分為 0 和 1 (圖片中有貓/沒貓; 有得病/沒得病; 會下雨;不會下雨…)
然而輸出結果只有 0 和 1,顯得不太精確。感知機對線性分類有效,無法處理線性不可分的問題。
什麼是線性可分、和線性不可分的問題呢?比如說切開西瓜,可以發現裡面有白色的籽和黑色的籽;如果白籽和黑籽的分佈,能讓我們用一刀切分開,就是線性可分;如果是要用橢圓或曲線才能切開,就是線性不可分。因此線性可分的意義在於——我們能不能單純用一條直線把兩團資料點切分開。
由於感知機只能解決線性可分的問題,但現實中的分類問題通常是非線性的。為了針對線性不可分問題,類神經網路領域又發展出了不同的激發函數,比如使用 Sigmoid 函數,將「圖片中有貓/沒貓」的 0 和 1 標籤、進一步細化成可能的機率──「圖片中有貓/沒貓」的機率是在 0 到 1 之間的任意實數,比如 0.8807… (x=2)、0.2689… (x=-1)。
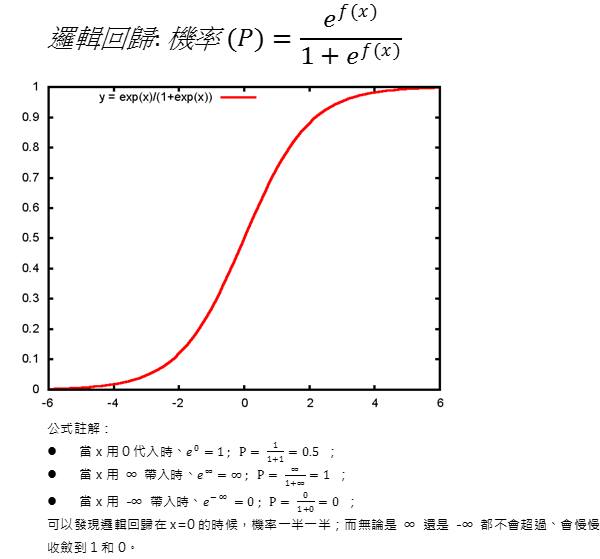
因此「Sigmoid 神經元」進一步被提了出來,使用 Sigmoid 函數作為神經元的激發函數。Sigmoid 函數即統計學上的邏輯回歸,因為圖形長得像一個 S 故有此稱。
機器學習的核心概念是從資料中自行學會一套技能,並根據新給的數據、自行更正預測錯誤的地方、不斷地優化技能。那麼究竟類神經網路是如何從錯誤中進行修正學習的呢? 神經網路的學習過程可以分成下列兩個步驟:
1. 前向傳播 (Forward-Propagation)
類神經網路採用監督式學習方法。在網絡中,每一個神經元都是一個激發函數;多個神經元連接在一起、形成一個類似生物神經網絡的網狀結構,並分成了好幾層。
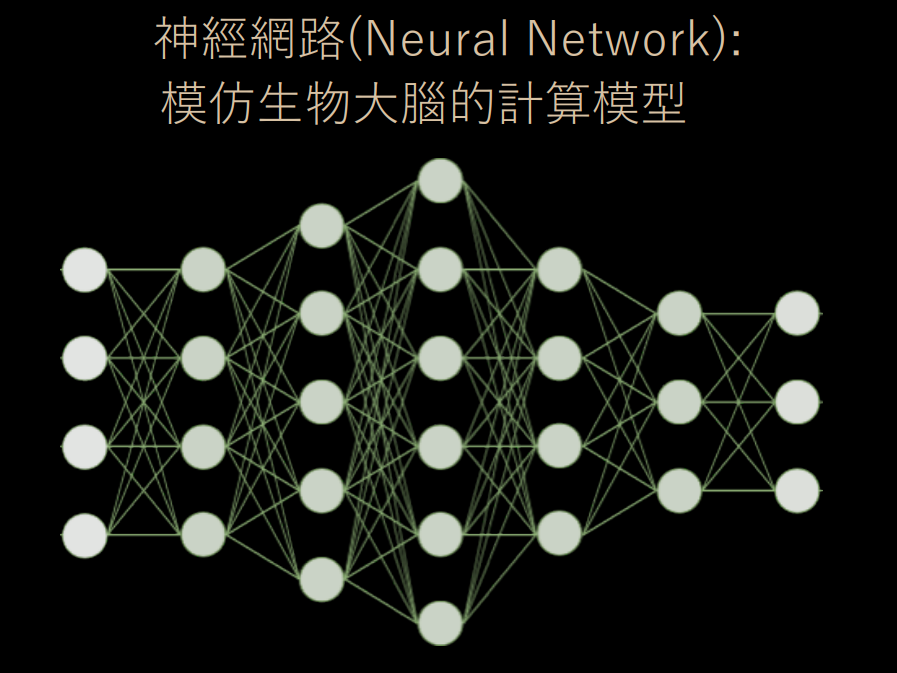
當機器學習第一次「看」到一隻貓咪的圖片資料時,會將貓咪圖片的特徵向量透過神經網路從左向右傳遞過去,中間會經過特定幾個神經元、經過各個神經元上的激發函數後產出最終的預測答案──比如最後預測出來的結果是 0.1,機器學習認為這張圖片裡面很可能沒有貓咪 (可能電腦認為牠是隻狗唄)。
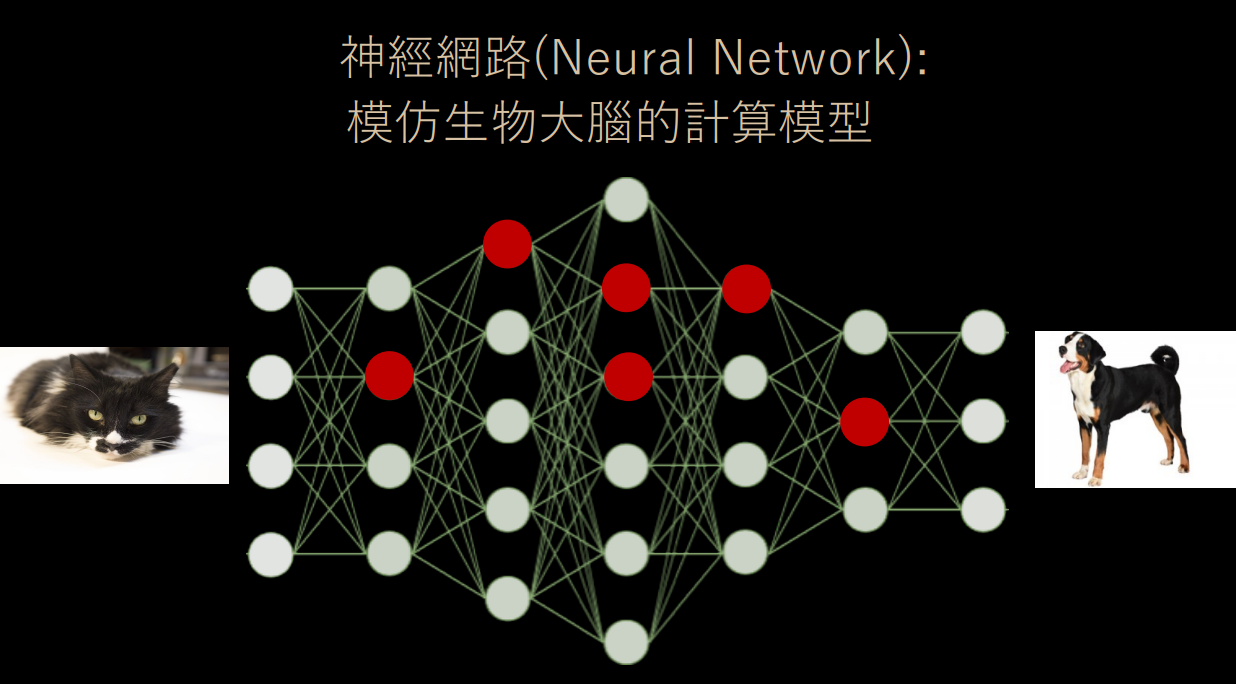
2. 反向傳播 (Backward-Propagation)
此時資料科學家會設定更正錯誤的方法──「代價函數」(Cost Function)。代價函數是預測結果和真實結果之間的差距。如果預測完全正確,則代價函數值為 0;如果代價函數值很高,則表示預測的偏誤很大。所以我們的目標便是將代價函數優化到越小越好。
當預測結果和真實結果不一致時,兩者間的差距越大就會讓代價函數越大;因此為了讓預測結果越接近目標值、也就是代價函數達到最小,我們會將這個結果從右到左反向傳遞回去,調整神經元的權重以找到代價函數的最小值。
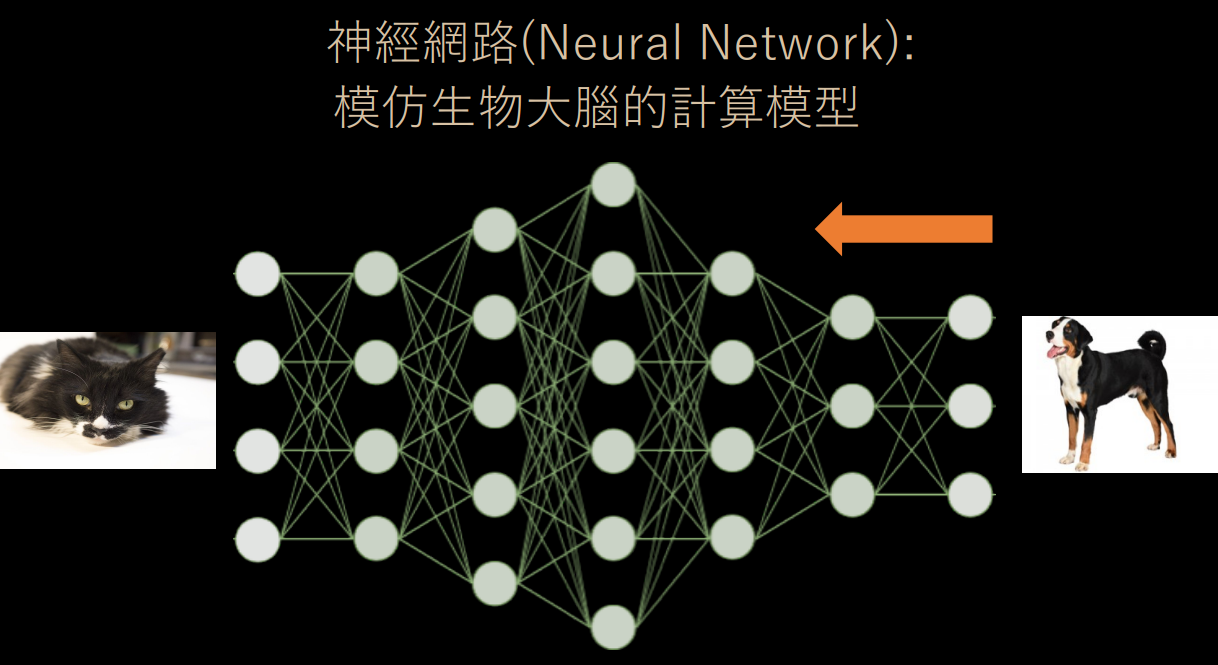
簡單來講,類神經網路就是先讓資料訊號通過網路,輸出結果後、計算其與真實情況的誤差。再將誤差訊號反向傳遞回去、對每一個神經元都往正確的方向調整一下權重。如此來回個數千萬遍後,機器就學會如何辨識一隻貓了。
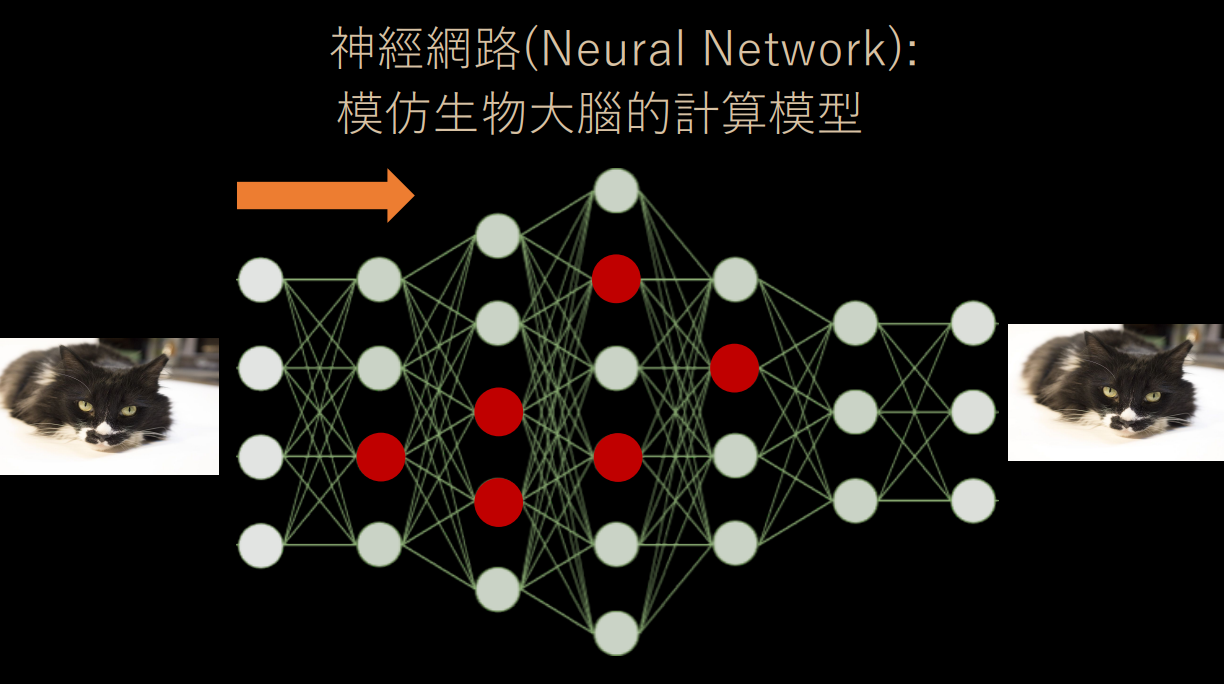
1986 年,Rumelhar 和 Hinton 等人提出了反向傳播算法,解決了神經網路所需要的複雜計算量問題,從而帶動了神經網路的研究熱潮。
此時的 Hinton 還很年輕,即便在後來神經網路遇到了瓶頸——反向傳播的優化 (找出誤差的最小值) 問題,學術界一度摒棄神經網路時,仍不離不棄對於神經網路的研究。也正是這股熱情,使得 30 年以後,正是他重新定義了神經網路、帶來了神經網路復甦的又一春;Hinton 也因此被稱為「深度學習之父」。
這邊,就讓我們來瞭解一下類神經網路究竟遇到了什麼問題,以致差點一厥不振。
梯度消失問題——多層神經網路的挑戰
當變數是線性關係時,代價函數J(Ө) ──也就是計算預測結果和實際真實數據之間的距離差距,可如此表示:
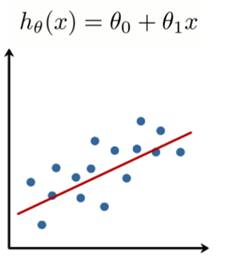
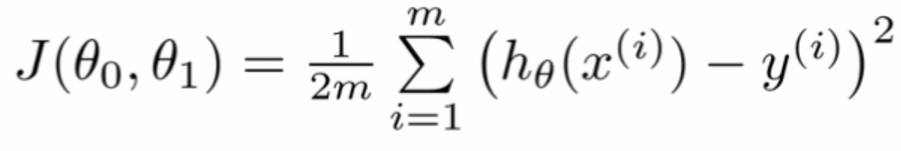
將公式用圖形畫出來,能發現是一個凸函數。可以想像我們將一顆球從最高點開始滾落、很快就能掉到這個山谷的谷底 (最小值)。
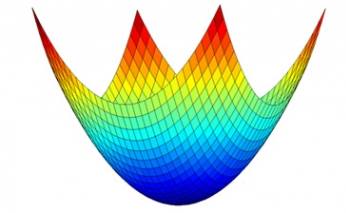
也就是說,在面對線性問題時,模型能夠很快地找到代價函數的最小值。
然而在真實世界中、變數之間的關係多半是非線性。比如當我們採用 Sigmoid 神經元時,由於 Sigmoid 函數不是線性函數,其代價函數 J(Ө) 便不是凸函數:
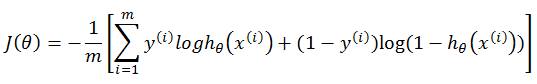
將 Sigmoid 神經元的代價函數圖形繪製出來後,可以發現在最高點丟下一顆球後,球可能會掉到某個下凹的地方就停止滾動了,然而那並非是全山谷最低的地方。也就是說,由於有多個局部最小值,我們很容易僅找到局部最小值、而非全域的最小值。
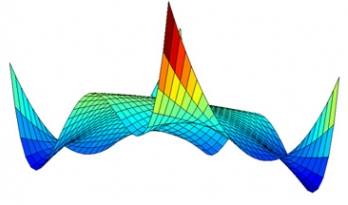
如果能透過微積分計算出斜率 (導數) 的話,我們可以計算出山坡上最陡峭的那一個方向,這種微積分概念稱為「梯度」。
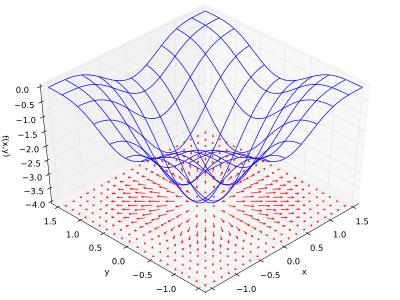
在上圖中,底下的平面上所畫的向量,就是上面那個曲面在該點的梯度,換句話說某一點的梯度其實是一個向量。
這種尋找代價函數最小值的方法稱為「梯度下降法」(Gradient Descent),透過微積分計算出斜率 (導數)、我們可以計算出山坡上最陡峭的那一個方向,這種微積分概念稱為「梯度」;只要朝著梯度的方向走去,就是最快下降的道路了。
至於要從山谷中的哪一個地方降落、開始往下走呢?我們可以先隨機選擇一个斜率為初始值,然後不斷地修改以减小,直到斜率為 0。如此稱為「隨機梯度下降法」(Stochastic Gradient Descent)。
機器學習相當注重優化 (Optimization) 的問題──如何用更快的方式逼近最佳解。電腦科學家會去想:我該優化什麼東西才好?要怎麼優化才會實際上增加我的收入、或解決某個實務上的問題?要用甚麼方法達成這個優化?
像是我們在梯度下降法中討論的收斂性值 (如何找到最低的谷底),即是機器學習的研究重點。機器學習重視實務問題上的使用情境差異,會嘗試解決各種不同的問題、並尋找最佳的優化方式。
一層層的類神經網路聽起來似乎很厲害。當年由 Hinton 等人首先提出了多層感知機、以及反向傳播的訓練算法,使得類神經網路在 1980 – 1990 年代鼎盛一時。然而問題很快就出現了,幾乎讓神經網路這個機器學習方法從此一蹶不振。這個問題叫做「梯度消失」(Vanishing Gradient)。
梯度下降法就像爬下谷底一樣,從一開始很快的往下跑,越接近谷底時每個一梯度會逐漸變小、慢慢逼近最小值。
我們在一開始提到過,類神經網路的原理就是先讓資料訊號通過網路,輸出結果後、計算其與真實情況的誤差。再將誤差訊號反向傳遞回去,透過梯度下降法,讓神經網路網路去逐一調整神經元的權重、不斷優化直到誤差最小、也就是代價函數達到最小值。
然而這種方法在神經網路具備多層的情況下,性能變得非常不理想,容易出現梯度消失問題——非線性問題的代價函數為非凸函數,求解時容易陷入局部最優解、而非全域最優解。
更糟的是,這種情況隨著神經網路層數的增加而更加嚴重,即隨著梯度逐層不斷消散、導致其對神經元權重調整的功用越來越小,所以只能轉而處理淺層結構(小於等於 3),從而限制了性能。
如果說為了不讓神經網路失真,僅能讓資料來回傳個 1、2 層,那還叫神經網路嗎?人類的大腦可就有數千萬層神經網路呢!與其使用理論難度高、訓練速度慢、實際結果也只能傳少少幾層的淺層神經網路的情況下不比其他方法好,不如使用其他的機器學習模型。
第二波浪潮: 淺層機器學習 (Shallow Learning)
神經網路由於遇到了優化的瓶頸,以致一度沒落。當時的學界只要看到出現「神經網路」字眼的論文或研究計畫,便會立刻貶斥。多層的神經網路是不可能的,而若採用僅有兩層的神經網路,不如使用其他更好上手、同樣只有兩層的「淺層」機器學習模型,
1990年代,各式各樣的淺層機器學習被提出,其中支撐向量機 (SVM, Support Vector Machines)最廣受歡迎。同樣是做資料的二分法,SVM 是怎麼做的呢?
要如何找出一條線、完美地將藍球和紅球切分開?且兩類群須距離這條線最遠、以確定兩群資料分得越開越好。這樣新進資料進來的時候才不會容易掉到錯誤的另外一邊、出現誤差 (Error)。
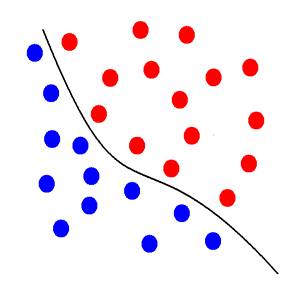
SVM 會將原始資料投影到一個更高維度的空間裡,在低維度不可切分的資料,在高維度便可以切分了。
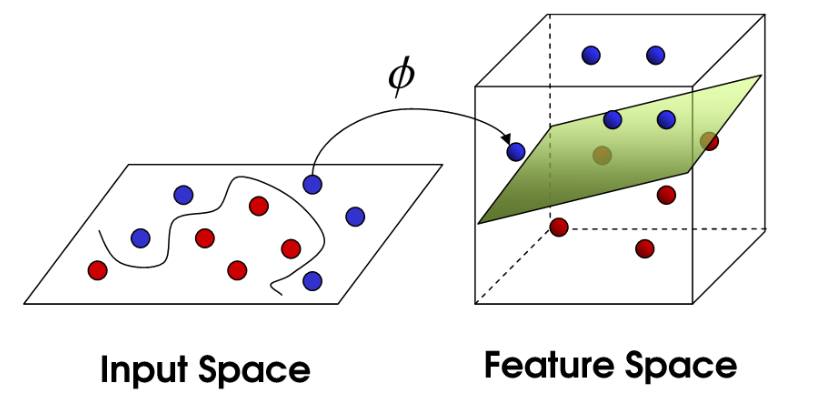
SVM 理論上更加嚴謹完備,上手簡單,得到主流學術界的追捧。此時人人都不相信神經網路的可能性。而支持向量機 (SVM) 技術在圖像和語音識別方面的成功,使得神經網絡的研究陷入前所未有的低潮。
此時學術界的共識是: 多層神經網路是個完全沒有前途的死胡同。
究竟是誰重新改變了這一切、讓多層神經網路在2006年時換上「深度神經網路」(Deep Neural Network; 又稱 Deep Learning, 深度學習) 的新名字、聲勢浩大地捲土重來呢? 還記得我們提過、對於神經網路不離不棄研究三十年的 Hinton 嗎?他是怎麼解決這個問題的呢?
在現今,深度學習已是人工智慧領域中成長最為快速的類別。下一篇就讓我們來聊聊深度學習之父──多倫多大學 Geoffrey Hinton 教授的故事,看看他是如何耗費三十年的時間、終於讓類神經網路重迎一絲曙光。